Home
-
ww2572 Wei Wang
- wrote the General Tutorial
-
hs3239 Hanfu Shi
- wrote the Problem and Solution part and gave a project example
-
SQL is the lingua franca for doing analytics. However, it's pain in the neck to connect big data processing pipelines like Spark or Hadoop on an SQL database. Also, traditional Hadoop Hive queries run slowly so a new query engine is needed.
-
Spark SQL is built as an Apache Spark module for working with structured data. Its main roles include seamlessly mixing SQL queries with Spark programs, connecting to all data sources in the same way, and Running SQL or HiveQL queries on existing warehouses. It enables unmodified queries to run 100x faster than the traditional way
-
Hive on spark is an alternative to Spark SQL. In fact, the two modules have the same contents. However, the spark industry focuses more on Spark SQL these years so it become more and more popular. Typically, hive on spark is slow and lacks thread security compared to Spark SQL
-
In 4111, we learned SQL, query execution, and optimization. Query speed and big data analysis is a crucial topic for modern data scientists and data engineers. Therefore, we think giving a tutorial for Spark SQL is helpful for those who want to dive deep into query execution and big data analysis and develop a career based on that. In the other words, our guide provides a different perspective to optimize query execution.
- Use the link to download the latest version of Spark.
- Install it using PyPi
!pip install pyspark
- Import Spark modules
Spark Session is the entry point of Spark, so we initialize SparkSession to use Spark.
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
There are multiple ways to create the same Dataframe.
- Use a list of rows
from pyspark.sql import Row
df = spark.createDataFrame([
Row(id=1, name='Wei', age=24, sex='Female', classes='Intro to databases'),
Row(id=2, name='Hanfu', age=25, sex='Male', classes='Intro to databases'),
Row(id=3, name='Xin', age=24, sex='Female', classes='Intro to databases')
])
- Use explicit schema
df = spark.createDataFrame([
(1, 'Wei', 24, 'Female', 'Intro to databases'),
(2, 'Hanfu', 25, 'Male', 'Intro to databases'),
(3, 'Xin', 24, 'Female', 'Intro to databases')
], schema='id long, name string, age long, sex string, classes string')
- Use Pandas DataFrame
import pandas as pd
pandas_df=pd.DataFrame(
{
'id': [1, 2, 3],
'name': ['Wei', 'Hanfu', 'Xin'],
'age': [24, 25, 24],
'sex': ['Female', 'Male', 'Female'],
'classes': ['Intro to databases', 'Intro to databases', 'Intro to databases']
})
df=spark.createDataFrame(pandas_df)
In addition, Spark DataFrame can also be converted to Pandas DataFrame.
df.toPandas()
All methods above create the same DataFrame
To show the data frame and schema from above
df.show()
df.printSchema()

- Show top rows
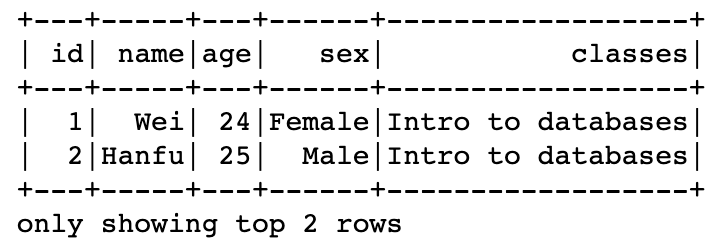
df.show(2)
# only show the first two rows of the data frame.
- Show rows vertically
df.show(2, vertical=True)
# If the row is too long, then you can make it vertically.

- Show column names
df.columns
['id', 'name', 'age', 'sex', 'classes']
- Show schema
df.printSchema()

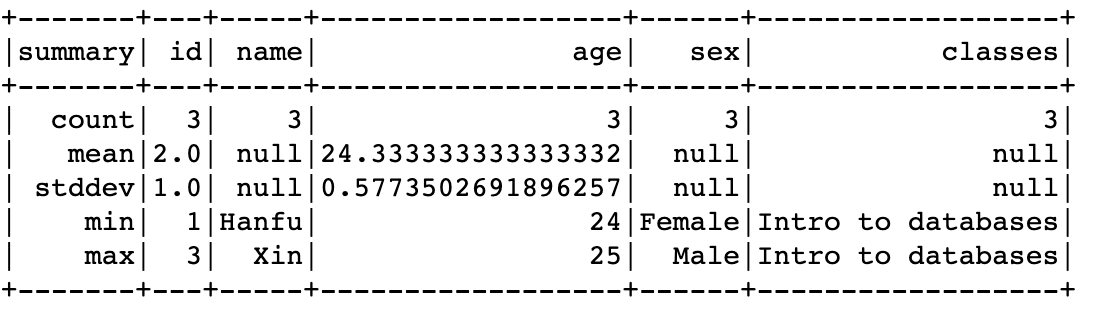
- Show summary
df.describe().show()
- Select columns and return them as a new DataFrame
# Both is the same
df.select(df.name).show()
df.select('name').show()
- Select specified rows of the data
df.filter(df.id==1).show()
df.where(df.id==1).show()
# only select data where id equals to 1.
- Group data and get statistics
df.groupby('sex').count().show()

- Import csv file
spark.read.csv('file_name.csv', header=True)
- Import JSON data
spark.read.json('file_name.json')
- Use the data frame to create a SQL temporary view
df.createOrReplaceTempView("2022Spring")
- Execute SQL query
sqlDF = spark.sql("SELECT name,classes FROM 2022Spring")
sqlDF.show()

sqlDF = spark.sql("SELECT name,classes FROM 2022Spring WHERE id=1")
sqlDF.show()

My project is a web application developed for communities of universities to sell something they do not need. It requires efficient queries and analysis with more and more people using this application. The following code gives a solution combining Collaboratory with Spark SQL
Suppose we have exported the user table into CSV file (1 million users in practice, 11 here). we want to query the table and analyze the data.
-
Download spark,jdk and findspark

-
Import os and set the environment

-
import SparkSession

-
load our data to csv

-
check the schema

-
Check all users who are older than 25

-
Calculate the average age

- A more complex query
