Beekeeper is a Customizable, Realtime Graphing built on MongoDB and cube. It is available under the GPL V3 License.
Beekeeper is also stable, scalable, and has been tested on a production environment for months without any notable issue.
Beekeeper has been benchmarked on a replicated MongoDB setup using 4 old HP Proliant G4 servers, with a collector on each of them and is able to collect up to 100,000 events/s on this setup.
Beekeeper doesn't really care about what your data is, and takes full advantages of pure JSON documents as an input. So you can mix both server metrics and web analytics in the same system, in real time.
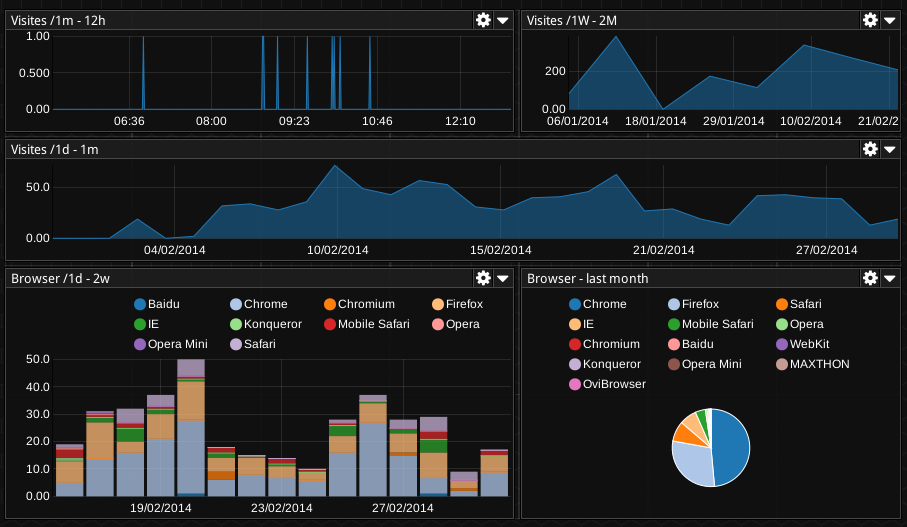
Beekeeper is based on Cube and adds a scalable collecting system, user dashboards with different kind of realtime widgets, some extended formula syntaxes, a formula completion system, and hierarchy (e.g. zone>datacenter>servers>etc.) awareness. We also work with notably Square and Infochimp in order to improve Cube by itself, but we maintain our own cube fork to have the full featureset we need for Beekeeper meanwhile.
It also includes a cluster-wide logging system, so you can debug easily what happens if you want to understand what happens during runtime.
Check you fulfill the Prerequisites, then simply clone the repository and install:
$> git clone https://github.com/worldline/beekeeper.git
$> npm install
$> npm start
Beekeeper runtime is separated in 4 independant parts, so you can scale easily what you need :
Collector is responsible for getting the raw JSON data you send to it into MongoDB.
It's an HTTP server and it puts any JSON into an event you can use in Beekeeper.
For raw server metrics, we usually use Collectd and SNMP together to put data into the collector.
Because raw data may not be simple to request, or maybe, because you use different sources to provide the same kind of data (say raw Collectd data and SNMP through Collectd data, providing data with a different name and different units, for the same purpose), it also provides ways to remap data before storing it.
You can have several collectors side by side, it's fully scalable.
Evaluator is responsible for doing the processing part needed to display your dashboards in realtime and creates the different caches needed to display it fast.
If you have several connected users applying different formulas at the time, you may want to scale the Evaluator
Introspector is in charge for analysing what you put in Beekeeper in the background, in order to provide you some completion while you use formulas.
It's pretty important, as Beekeeper doesn't enforce what you put into it, and you will need some help in order to type your formulas if you don't want to go in MongoDB to see the raw collected data
Admin is the frontend you show as a user. It manages the dashboards,the users, auth, widget creation, formulas, etc.
Technically, it is by itself splitted in 2 parts: static content and dynamic content.
You can scale these parts independently too !
While documentation is not complete yet, most of what is available is in this file