Source codes for our paper "Neural Temporality Adaptation for Document Classification: Diachronic Word Embeddings and Domain Adaptation Models" at ACL 2019.
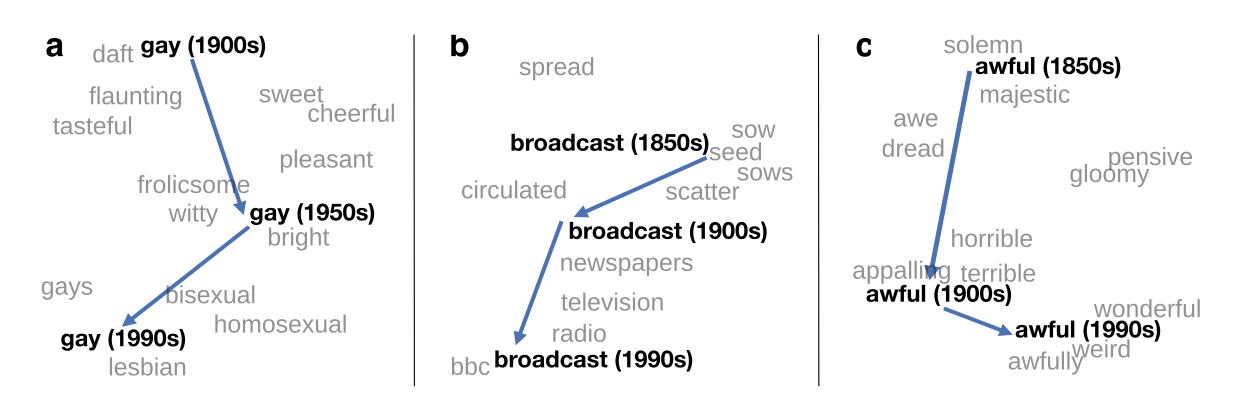
Image is from https://nlp.stanford.edu/projects/histwords/
The meanings of words shift overtime~ This will bring tremendous effects on document models.

Overall, it is clear that classifiers generally perform best when applied to the same time interval they were trained. Performance diminishes when applied to different time intervals, although different corpora exhibit differ patterns in the way in which the performance diminishes. The image is from our previous publication, Examining Temporality in Document Classification.
We propose a diachronic word embedding using fastText. See the readme.md for how to train.
- Train it once, run everywhere. The embedding model just like normal word embedding model, we don't need to train additional equations after training your embeddings. All you need to do is to only train your embeddings once. No extra time needed.
- No Transformation Matrix and Transformation Errors. Since the trained model learn words across time jointly, it does not require to learn transformation matrices between time intervals.
- No extra space needed. Our method only requires the space for the embedding models.
- Support online learning and incremental training. Unlike other methods, our proposed method can incrementally learn new coming corpora.
- Extensible word vocabulary. Unlike the transformation or pivot method, our proposed method do not need to choose a fix number of vocabulary as the transformation matrix. Our method supports extensible words even from the new coming data.

We explore and analyze the shifts from three perspectives:
- Word usage change: the way to express opinions change;
- Word context change: contextual words are important parts to train word embeddings. The change of contextual words impact word embeddings and therefore neural document classifiers based on word embeddings.
- Semantic distance: after obtaining diachronic word embeddings, we treat each time period as a domain and then use Wasserstein distance to measure time shifts.
Generally, closer time intervals share higher overlap and have smaller semantic distance shifts, and vice versa.
Our method is also useful for interpreting semantic shifts. The visualization below can help select features for the time-varying corpora: polysemous features (unigram) have shown more semantic variations than the most frequent features (unigram). Note that there are no overlaps between the most frequent and the polysemous feature sets.

The polysemous words were selected by the mutual information (feature selection process). Those words are recognized as the most important features and used for classifying documents. However variations of the features will impact stabilities of document classifiers over time.
Python 3.6+, Ubuntu 16.04
- Install Conda and then install required Python packages via
pip install -r requirements.txt; - Train and obtain regular and diachronic word embeddings. Please refer to readme.md in the
embeddingsfolder; - Create domain data:
python create_domain_data.py; - Create general and domain tokenizers:
python create_domain_tokenizer.py; - Create weights for the embedding layer:
python create_weights.py; - Create train/valid/test data: You can either download our processed split data or run
python create_split_data.py; - Convert data into indices:
python create_word2idx.py.
- Please refer to the
analysisfolder. - There are three main analysis perspectives: word usage, word context and semantic distance.
- To understand topic shifts and how the temporal factor impacts document classifers, please refer to our previous publication and its git repository.
- Please refer to the readme.md in the
baselinesfolder. - The datasets of baselines will be saved in the
baselines_datafolder.
We conducted an intrinsic evaluation by a clustering task of word analogy. The evaluation will be available in my final Ph.D. thesis, while the manuscript was not published in the paper. You can refer to the experimental steps in this unpublished manuscript.

Because the experimental datasets are too large to share all of them. Please send any requests or questions to my email: [email protected].
Please consider cite our work as the following:
@inproceedings{huang-paul-2019-diachronic,
title = "Neural Temporality Adaptation for Document Classification: Diachronic Word Embeddings and Domain Adaptation Models",
author = "Huang, Xiaolei and Paul, Michael J.",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://cmci.colorado.edu/~mpaul/files/acl2019_temporality.pdf",
pages = "136--146",
abstract = "Language usage can change across periods of time, but document classifiers models are usually trained and tested on corpora spanning multiple years without considering temporal variations. This paper describes two complementary ways to adapt classifiers to shifts across time. First, we show that diachronic word embeddings, which were originally developed to study language change, can also improve document classification, and we show a simple method for constructing this type of embedding. Second, we propose a time-driven neural classification model inspired by methods for domain adaptation. Experiments on six corpora show how these methods can make classifiers more robust over time.",
}