You can use this master branch as a skeleton java project
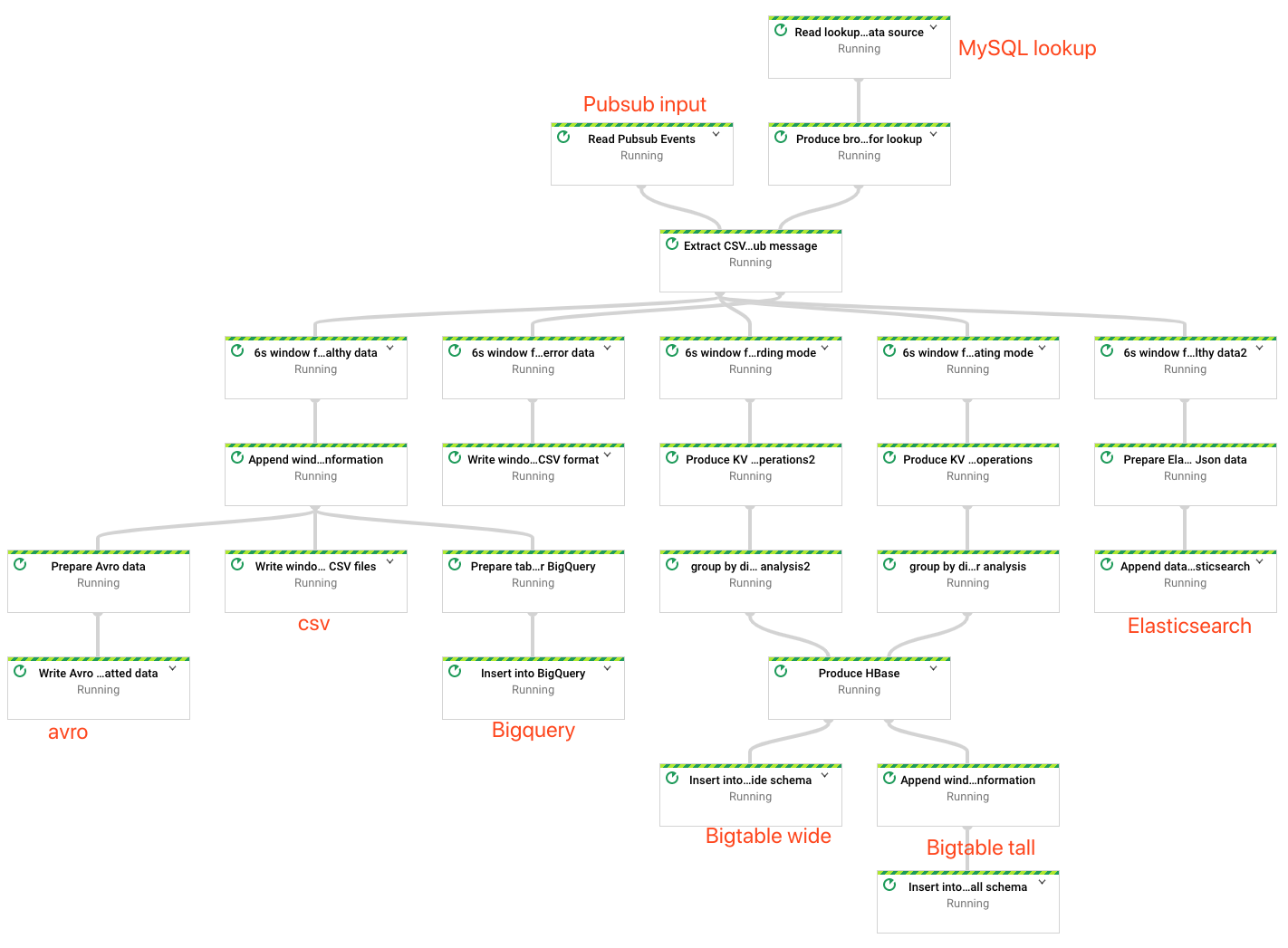
pubsub -> dataflow -> GCS(avro, csv for both data & deadleter) + BigQuery
Java dev environment
- JDK8+
- Maven
This branch is focusing on streaming, so the sample subscribes messages from Pubsub. It's easy to switch to KafkaIO in beam. But the quickest way to produce some dummy data then send to Pubsub for fun is by using this project.
If you use the GCP Play Ground to produce the pubsub message, there isn't much to do. Simply update the run shell script, make sure you have the corresponding permissions to manipulate the GCP resources. Then
./run df
- Do I need to setup the BigQuery table in advance?
A: No. The application will create for you, and append to existing table by default.
- How to control the permissions?
A: This project is currently relying on the service account specified by the GOOGLE_APPLICATION_CREDENTIALS environment variable. Consult here for details.