These are intermediate files that should provide different starting point for observing the rank-frequency relationship or Zipf's Law in Brown University Standard Corpus of Present-Day American English. This relationship was first observed by Henry Kucera and W. Nelson Francis on log-graph paper.
- If you want to start from scratch, get
gen_word_freq.py. - If you want the rank-freq counts, get
word_freq.csv/.7z.
I started this repo because I wanted to verify power laws in data for myself after reading Newman. You can see common methods of verification in my results below.
-
Log-log plotting:
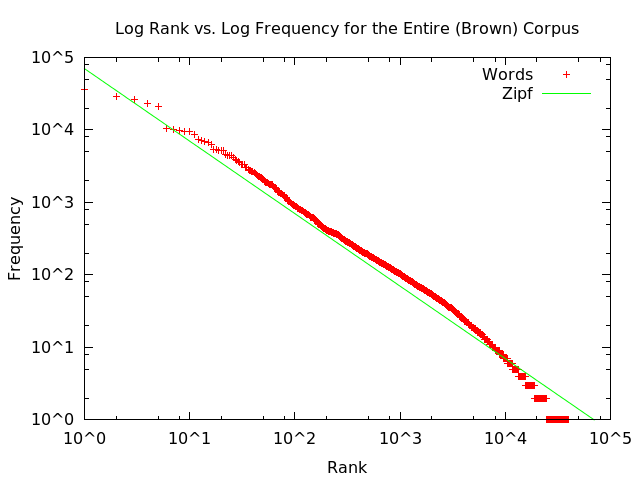
-
Logarithmic Binning:
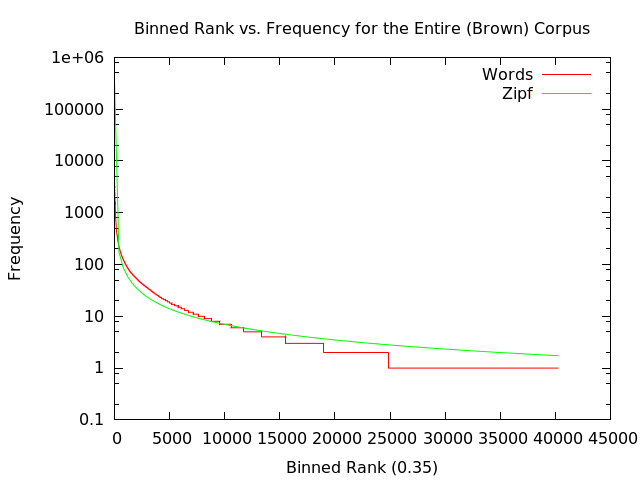
This method is a bit of an overkill because there is little scatter in the tail. Consequently, the graph would have looked like the one above so instead I made the x-axis linear to illustrate the binning process -- the width of which was calculated using Freedman-Diaconis rule.
- Cumulative Density Function
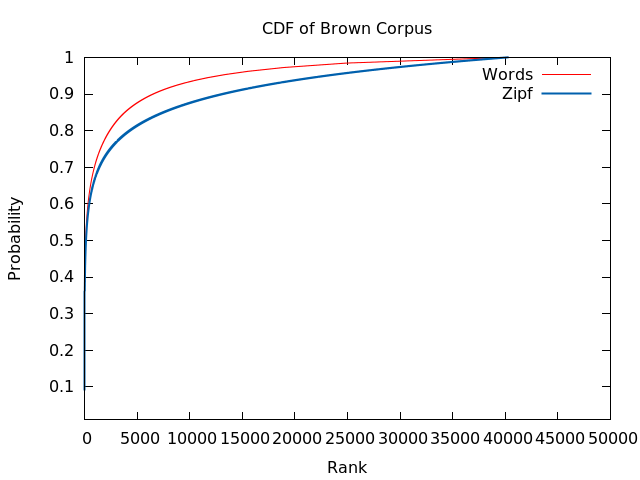
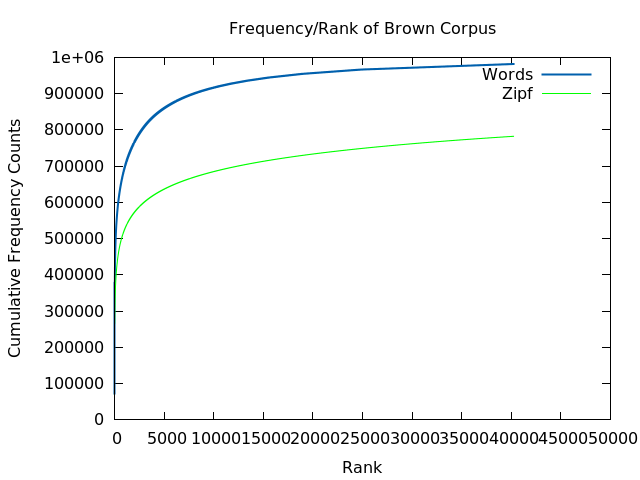
Notice that the CDFs are rather different. Had started with this you might not agree that Brown's Corpus follows zipf at all. I suppose this is what they mean by 'empirical power laws' being approximation. We can test whether they are really similar or different with Kolmogorov-Smirnov test. We can observe visually that the D value is ~0.1, and the critical value is ~0.002 (sqrt((981716+782254)/(981716*782254))*1.36), ~0.1 >> ~0.002 hence we reject the null hypothesis that the two are from the same underlying probablity distribution.
This is an interesting result because for 50 years people have been making the claim that word frequency follows Zipf's law on the basis that Brown Corpus follows Zipf's law. This is not entirely true. Brown's Corpus is Zipfian only over its middle values -- ignoring both tails.
Probably no one remembers a prophetic little comment by Twaddell where he warns that "the tables and graphs dealing with fits to a "Zipf's constant" line show a suggestively narrow range of variation with hints of dependence on sample size. It would be equally injudicious to be awed by the display or to dimiss it as unimportant." -- The Forward, Computational Analysis of Present-Day American English, where the result was originally published.
Thanks for reading. Have fun!
Notes to self:
- I have used the 2 sample ks test because it is easier to follow on wikipedia. The 1 sample ks goodness of fit test would give the same result.
- The zip file is generated as follows:
7z a -t7z -m0=lzma -mx=9 -mfb=64 -md=32m -ms=on word_freq.7z word_freq.csv