大模型的量化之路——transformers是如何给模型添加上量化功能的【transformers源码阅读】
- 现在 nlp 模型,动不动就 7b、13b 的,有的甚至更大,如果直接使用 bfloat16 加载推理、训练,需要太大的显存了。
- 于是现在大家都在用 int4、int8 对这种 100b 以上的模型、对 60b 以上的模型做量化。量化之后的模型,虽然效果会变差,但是好像效果还不错。
- 有的人,甚至结合 lora,做了 qlora。比如这个项目https://github.com/artidoro/qlora,现在很火~
- 现在,在最新的 transformers 包里面,已经集成了相关的方法,你可以使用 int4、int8 对任何 transformers 家族的模型做量化。而且就传递几个参数即可。很简单。
- 现在的 int4、int8 方法实现,包括 transformers 集成的量化方法,基本上都是基于 bitsandbytes 包的。
- 我就是很好奇,transformers 包,到底怎么做的,就加个参数,就可以量化模型了。
- 这个量化,到底是怎么量化的。懒得看论文了,就看代码吧。
接下来,我们就逐步深入,看看他这个怎么一回事儿
- 下面这个代码,是从那个 qlora 仓库里面,复制出来的。
- 也就是说,只要在代码里面,给
quantization_config参数,传递一个BitsAndBytesConfig对象,即可在模型初始化的时候,先对模型做量化。
# https://github.com/artidoro/qlora/blob/main/qlora.py#L268
model = AutoModelForCausalLM.from_pretrained(
args.model_name_or_path,
cache_dir=args.cache_dir,
load_in_4bit=args.bits == 4,
load_in_8bit=args.bits == 8,
device_map='auto',
max_memory=max_memory,
quantization_config=BitsAndBytesConfig(
load_in_4bit=args.bits == 4,
load_in_8bit=args.bits == 8,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=args.double_quant,
bnb_4bit_quant_type=args.quant_type
),
torch_dtype=(torch.float32 if args.fp16 else (torch.bfloat16 if args.bf16 else torch.float32)),
trust_remote_code=args.trust_remote_code,
)先来定位BitsAndBytesConfig这个类在哪里,还是比较简单的,直接在 pycharm 里面搜索就行了,在transformers/utils/quantization_config.py里面。
在这个类里面,定义了量化行为,具体不解释了。
在看到transformers/utils/quantization_config.py文件的时候,我又发现:在transformers/utils/文件夹下,还有一个文件叫bitsandbytes.py

我当时感觉,这个文件,肯定和量化的操作相关,如果没关系,不可能起的名字和bitsandbytes包一样吧。不管有没有用,先把这个文件看完了再说。
实际上,在这个文件里面,有一个非常重要的函数replace_with_bnb_linear,而这个函数,又依靠另外一个函数,叫_replace_with_bnb_linear.
这两个函数,做的事情,就是要使用bnb.nn.Linear4bit或者bnb.nn.Linear8bit模块把一个模型里面所有nn.Linear模块,全部替换掉。
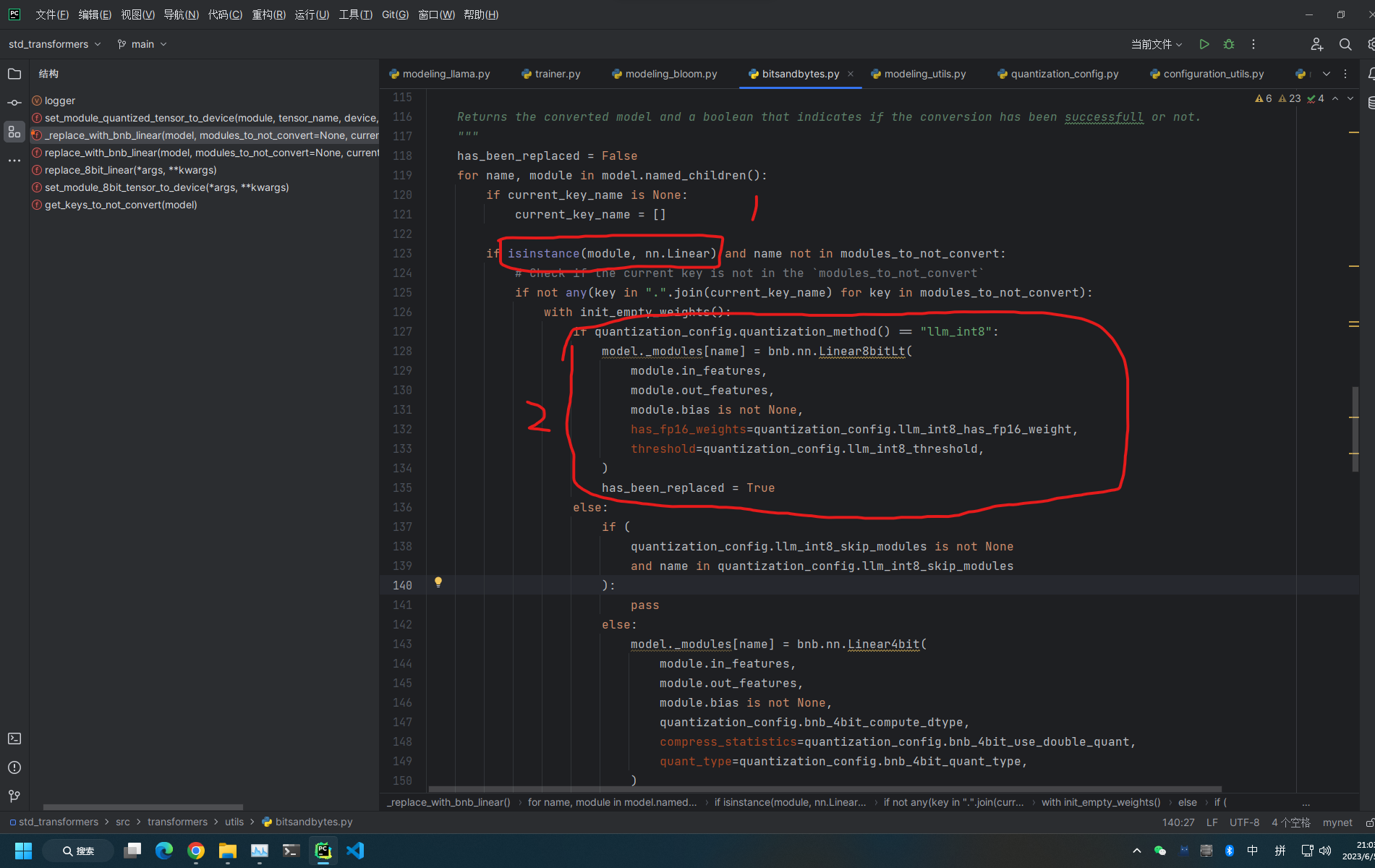
奥,笑死,搞了半天,所谓的量化,就是要把模型的nn.Linear全部被bitsandbytes.nn.Linear4(8)bit替换掉呗。
当然,也不是也有例外,就是不能把模型的lm_head层替换掉。(具体原因,我还没有研究)。
同时,在函数的注释里面,还大概介绍了 int8 的混合精度矩阵分解计算步骤:
Int8 mixed-precision matrix decomposition works by separating a
matrix multiplication into two streams: (1) and systematic feature outlier stream matrix multiplied in fp16
(0.01%), (2) a regular stream of int8 matrix multiplication (99.9%). With this method, int8 inference with no
predictive degradation is possible for very large models (>=176B parameters).大概的意思是将int8的混合精度矩阵分解通过将矩阵乘法分为fp16的离散特征值处理、常规的int8精度矩阵乘法两个部分。(这个部分不太懂,大佬们指导一下,后续我再看一下代码)。
那可以看出这个部分,再transformers的量化功能里面,还是非常重要的。
既然已经知道量化操作,主要是对nn.Linear做替换,那么在模型初始化的哪一步里面,做了这个步骤。
其实这个大概搜一下就可以找到。在文件transformers/modeling_utils.py里面,就可以找到
model = replace_with_bnb_linear(
model, modules_to_not_convert=modules_to_not_convert, quantization_config=quantization_config
)
# training in 8-bit is only available in 0.37.0+
model._is_quantized_training_enabled = version.parse(
importlib_metadata.version("bitsandbytes")
) >= version.parse("0.37.0")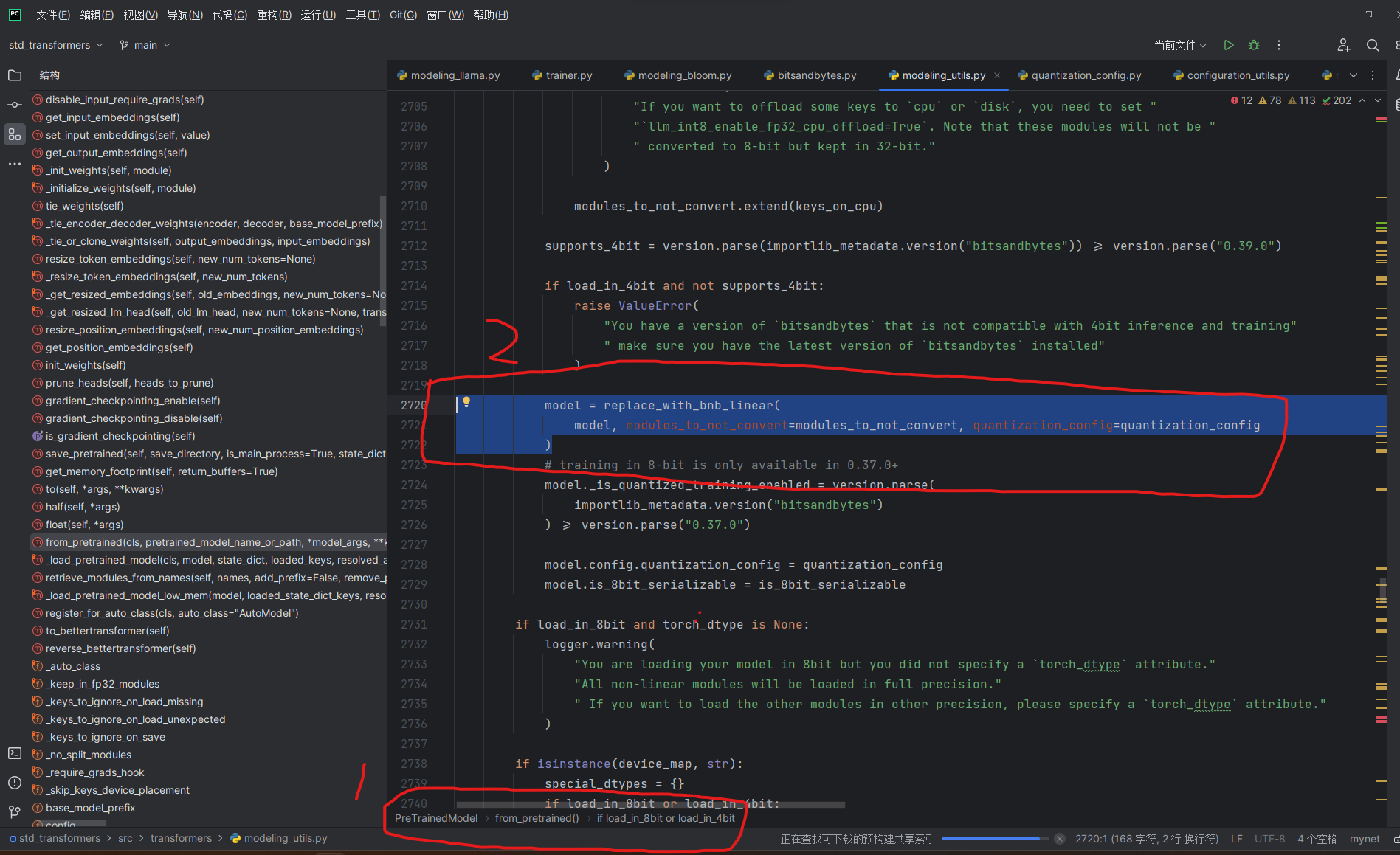
很显然,所有的模型,都继承了这个类PreTrainedModel,自然都可以拥有这个功能。(感觉有点是废话)。
- 知道,所谓的量化,就是使用
bitsandbytes.nn.Linear4(8)bit替换模型的所有的nn.Linear。但是不能替换模型的lm_head层。 - 大概知道transformers如何帮助模型拥有量化功能。
- 大概知道量化的解决方法(实际上,这部分是属于
bitsandbytes包的部分,这部分等我后面研究一下)。 - 如果对lora有点了解的话,其实可以知道lora方法,也就是对
nn.Linear层加了一个旁路。 - 一篇下来,emmm,就是感觉
nn.Linear真的是不容易,笑死。
- 喜欢阅读
transformers源码,对nlp和transformers包感兴趣。如果你对自然语言处理、文本转向量、transformers、大模型、gpt等内容感兴趣欢迎关注我~