This directory contains official implementations for Bayesian optimisation & Reinforcement Learning works developped by Huawei, Noah's Ark Lab.
- Bayesian Optimisation Research
- Reinforcement Learning Research
Further instructions are provided in the README files associated to each project.

Bayesian optimsation library developped by Huawei Noahs Ark Decision Making and Reasoning (DMnR) lab. The winning submission to the NeurIPS 2020 Black-Box Optimisation Challenge.


Codebase associated to: High-Dimensional Bayesian Optimisation with Variational Autoencoders and Deep Metric Learning
We introduce a method based on deep metric learning to perform Bayesian optimisation over high-dimensional, structured input spaces using variational autoencoders (VAEs). By extending ideas from supervised deep metric learning, we address a longstanding problem in high-dimensional VAE Bayesian optimisation, namely how to enforce a discriminative latent space as an inductive bias. Importantly, we achieve such an inductive bias using just 1% of the available labelled data relative to previous work, highlighting the sample efficiency of our approach. As a theoretical contribution, we present a proof of vanishing regret for our method. As an empirical contribution, we present state-of-the-art results on real-world high-dimensional black-box optimisation problems including property-guided molecule generation. It is the hope that the results presented in this paper can act as a guiding principle for realising effective high-dimensional Bayesian optimisation.

Codebase associated to: BOiLS: Bayesian Optimisation for Logic Synthesis accepted at DATE22 conference.
Optimising the quality-of-results (QoR) of circuits during logic synthesis is a formidable challenge necessitating the exploration of exponentially sized search spaces. While expert-designed operations aid in uncovering effective sequences, the increase in complexity of logic circuits favours automated procedures. Inspired by the successes of machine learning, researchers adapted deep learning and reinforcement learning to logic synthesis applications. However successful, those techniques suffer from high sample complexities preventing widespread adoption. To enable efficient and scalable solutions, we propose BOiLS, the first algorithm adapting modern Bayesian optimisation to navigate the space of synthesis operations. BOiLS requires no human intervention and effectively trades-off exploration versus exploitation through novel Gaussian process kernels and trust-region constrained acquisitions. In a set of experiments on EPFL benchmarks, we demonstrate BOiLS's superior performance compared to state-of-the-art in terms of both sample efficiency and QoR values.

Codebase associated to: Are we Forgetting about Compositional Optimisers in Bayesian Optimisation? accepted at JMLR.
Bayesian optimisation presents a sample-efficient methodology for global optimisation. Within this framework, a crucial performance-determining subroutine is the maximisation of the acquisition function, a task complicated by the fact that acquisition functions tend to be non-convex and thus nontrivial to optimise. In this paper, we undertake a comprehensive empirical study of approaches to maximise the acquisition function. Additionally, by deriving novel, yet mathematically equivalent, compositional forms for popular acquisition functions, we recast the maximisation task as a compositional optimisation problem, allowing us to benefit from the extensive literature in this field. We highlight the empirical advantages of the compositional approach to acquisition function maximisation across 3958 individual experiments comprising synthetic optimisation tasks as well as tasks from Bayesmark. Given the generality of the acquisition function maximisation subroutine, we posit that the adoption of compositional optimisers has the potential to yield performance improvements across all domains in which Bayesian optimisation is currently being applied.
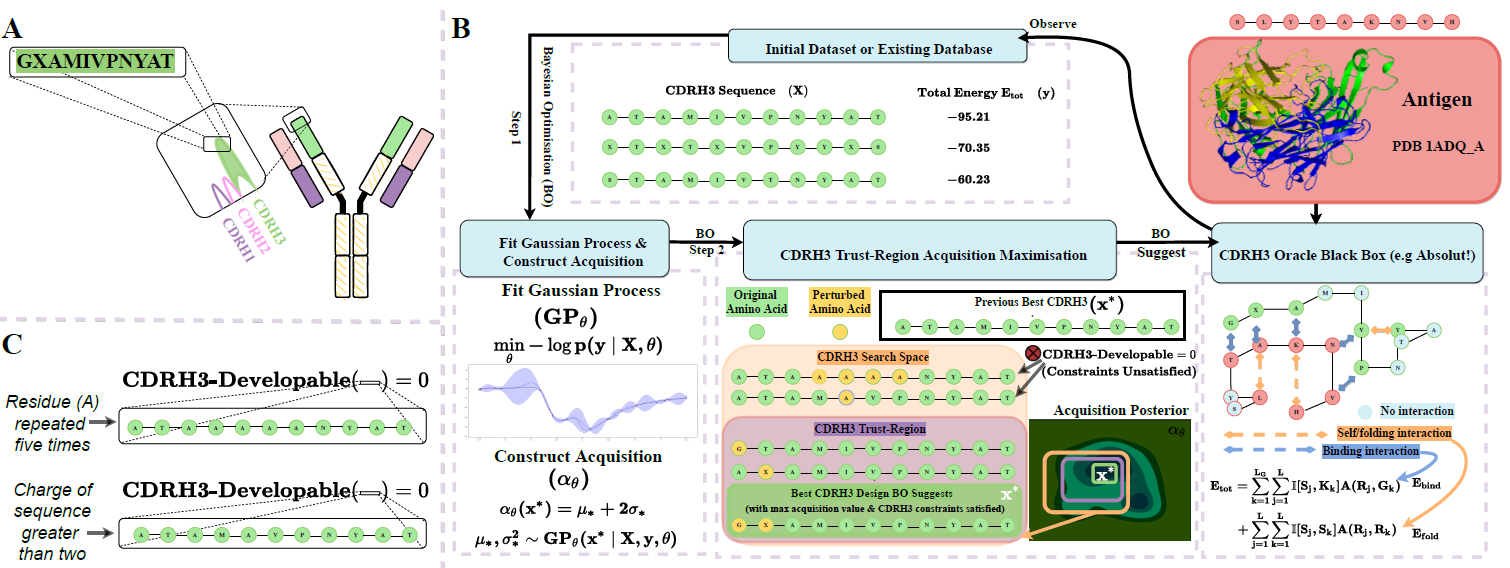
Codebase associated to: AntBO: Towards Real-World Automated Antibody Design with Combinatorial Bayesian Optimisation.
Antibodies are canonically Y-shaped multimeric proteins capable of highly specific molecular recognition. The CDRH3 region located at the tip of variable chains of an antibody dominates antigen-binding specificity. Therefore, it is a priority to design optimal antigen-specific CDRH3 regions to develop therapeutic antibodies to combat harmful pathogens. However, the combinatorial nature of CDRH3 sequence space makes it impossible to search for an optimal binding sequence exhaustively and efficiently, especially not experimentally. Here, we present AntBO: a Combinatorial Bayesian Optimisation framework enabling efficient in silico design of the CDRH3 region. Ideally, antibodies should bind to their target antigen and be free from any harmful outcomes. Therefore, we introduce the CDRH3 trust region that restricts the search to sequences with feasible developability scores. To benchmark AntBO, we use the Absolut! software suite as a black-box oracle because it can score the target specificity and affinity of designed antibodies in silico in an unconstrained fashion. The results across 188 antigens demonstrate the benefit of AntBO in designing CDRH3 regions with diverse biophysical properties. In under 200 protein designs, AntBO can suggest antibody sequences that outperform the best binding sequence drawn from 6.9 million experimentally obtained CDRH3s and a commonly used genetic algorithm baseline. Additionally, AntBO finds very-high affinity CDRH3 sequences in only 38 protein designs whilst requiring no domain knowledge. We conclude AntBO brings automated antibody design methods closer to what is practically viable for in vitro experimentation.
Codebase associated to: Sauté RL: Almost Surely Safe RL Using State Augmentation and Enhancing Safe Exploration Using Safety State Augmentation.
Satisfying safety constraints almost surely (or with probability one) can be critical for deployment of Reinforcement Learning (RL) in real-life applications. For example, plane landing and take-off should ideally occur with probability one. We address the problem by introducing Safety Augmented (Saute) Markov Decision Processes (MDPs), where the safety constraints are eliminated by augmenting them into the state-space and reshaping the objective. We show that Saute MDP satisfies the Bellman equation and moves us closer to solving Safe RL with constraints satisfied almost surely. We argue that Saute MDP allows to view Safe RL problem from a different perspective enabling new features. For instance, our approach has a plug-and-play nature, i.e., any RL algorithm can be "sauteed". Additionally, state augmentation allows for policy generalization across safety constraints. We finally show that Saute RL algorithms can outperform their state-of-the-art counterparts when constraint satisfaction is of high importance.
Safe exploration is a challenging and important problem in model-free reinforcement learning (RL). Often the safety cost is sparse and unknown, which unavoidably leads to constraint violations -- a phenomenon ideally to be avoided in safety-critical applications. We tackle this problem by augmenting the state-space with a safety state, which is nonnegative if and only if the constraint is satisfied. The value of this state also serves as a distance toward constraint violation, while its initial value indicates the available safety budget. This idea allows us to derive policies for scheduling the safety budget during training. We call our approach Simmer (Safe policy IMproveMEnt for RL) to reflect the careful nature of these schedules. We apply this idea to two safe RL problems: RL with constraints imposed on an average cost, and RL with constraints imposed on a cost with probability one. Our experiments suggest that simmering a safe algorithm can improve safety during training for both settings. We further show that Simmer can stabilize training and improve the performance of safe RL with average constraints.
Code associdated to: Model-Based Offline Reinforcement Learning with Pessimism-Modulated Dynamics Belief accepted at NeurIPS22 conference.
Model-based offline reinforcement learning (RL) aims to find highly rewarding policy, by leveraging a previously collected static dataset and a dynamics model. While learned through reuse of static dataset, the dynamics model's generalization ability hopefully promotes policy learning if properly utilized. To that end, several works propose to quantify the uncertainty of predicted dynamics, and explicitly apply it to penalize reward. However, as the dynamics and the reward are intrinsically different factors in context of MDP, characterizing the impact of dynamics uncertainty through reward penalty may incur unexpected tradeoff between model utilization and risk avoidance. In this work, we instead maintain a belief distribution over dynamics, and evaluate/optimize policy through biased sampling from the belief. The sampling procedure, biased towards pessimism, is derived based on an alternating Markov game formulation of offline RL. We formally show that the biased sampling naturally induces an updated dynamics belief with policy-dependent reweighting factor, termed Pessimism-Modulated Dynamics Belief. To improve policy, we devise an iterative regularized policy optimization algorithm for the game, with guarantee of monotonous improvement under certain condition. To make practical, we further devise an offline RL algorithm to approximately find the solution. Empirical results show that the proposed approach achieves state-of-the-art performance on a wide range of benchmark tasks.
Current contributors: Antoine Grosnit, Alexandre Max Maravel, Taher Jafferjee, Wenlong Lyu, Kaiyang Guo.
Alumni contributors: Alexander I. Cowen-Rivers, Aivar Sootla, Ryan Rhys Griffiths, Zhi Wang.