To keep up with the fast moving ML/DS space, I wanted a registry of curated content that I found useful and might want to refer to in the future. The large number of blogposts and the variety of content covered makes it difficult to manually tag entries and organize them in a principled manner.
I built a web app that takes as input a curated list of sources (blogs, newsletter, websites) and queries their RSS feeds. The HTML pages retrieved are parsed to retrieve <article> tags and be formatted to the hierarchical Article and Paragraphs schemas.
The text objects are embedded using the Contextionary Weaviate module. This stores both the raw text and the vector representation. Objects can be queried using the Weaviate GraphQL API. I built a GUI for for simple "keyword" and "concept" (vector) searches.
The embedding defined by the Contextionary can be queried to retrieve nearest neighbors. Also, concepts can be added to the Contextionary by writing a text definiton. Existing concepts can be modified with new definition to tune the embedding for your use case.
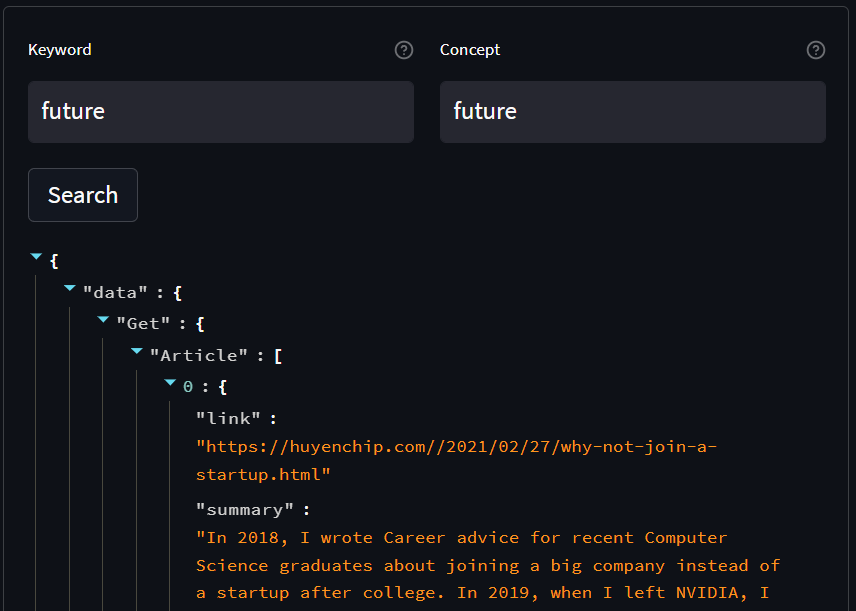
For the keyword query "future", the sorted results are:
- ""Validating your data with Hamilton"
- "Deployment for Free -- A Machine Learning Platform for Stitch Fix's Data Scientists"
- "Introduction to streaming for data scientists"
For the semantic query "future", the sorted results are:
- "Explosion in 2021: Our Year in Review"
- "7 reasons not to join a startup and 1 reason to"
- "Machine Learning Tools Landscape v2 (+84 new tools)"
For the query "future" for both keyword + semantic:
- "7 reasons not to join a startup and 1 reason to"
- "Enabling Creative Expression with Concept Activation Vectors"
- "Towards Helpful Robots: Grounding Language in Robotic Affordances"
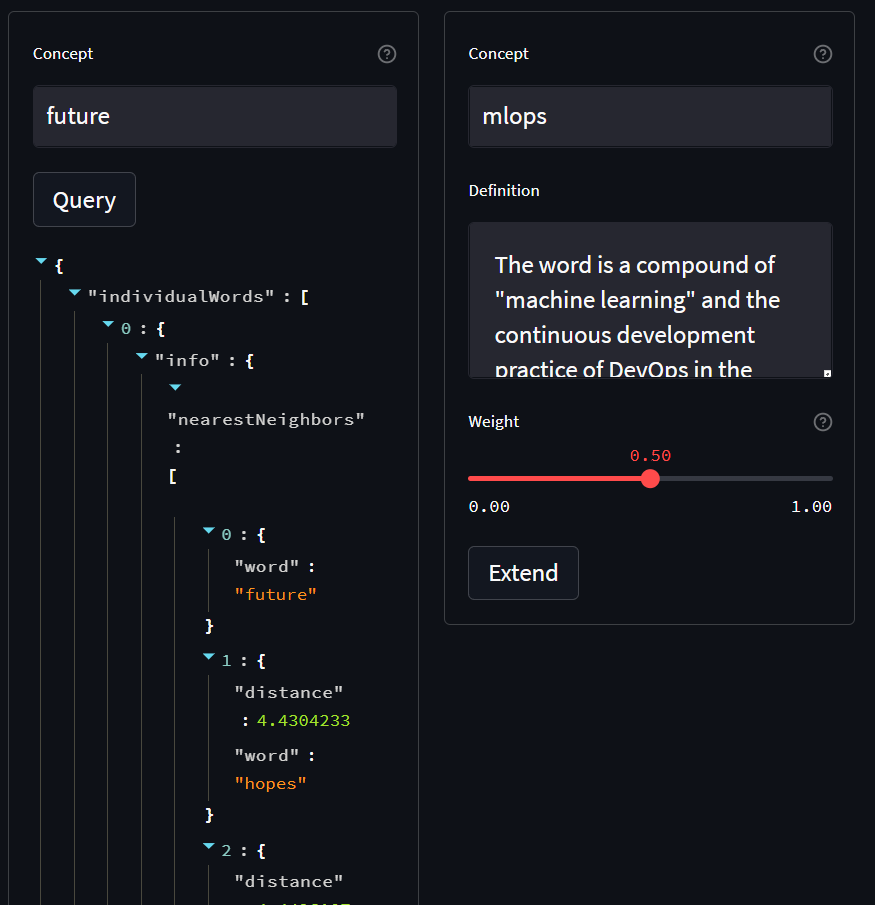
Default nearest neighbor for "future":
- hopes
- bringing
- potential
Default nearest neighbor for "mlops:
- "ops"
- "yongsonpa"
- "pluginbenchmarkaddon"
After defining "mlops" using wikipedia passages:
- developed
- relies
- demonstrate (That's a step in the right direction!)