Running Experiments
FlowEmu comes with an extensive toolchain for running automated experiments.
The bases for running experiments in FlowEmu is a testcases file.
The testcases files are written in TOML and located in the config/testcases directory.
An example is given below.
[metadata]
name = "iPerf"
description = "iPerf test case with different buffer sizes at the bottleneck"
author = "Daniel Stolpmann <[email protected]>"
[general]
disabled = true
graph-file = "fixed_interval"
source-command = "iperf -c 10.0.2.1 -t 10 -Z cubic"
sink-command = "iperf -s"
repetitions = 2
[shallow-buffer]
fifo_queue.buffer_size = 10
[deep-buffer]
fifo_queue.buffer_size = 100
[study]
fifo_queue.buffer_size = "[10, 100]"
[python]
fifo_queue.buffer_size = "[i*10 for i in [1, 10]]"
[scripted]
source-command = "iperf -c 10.0.2.1 -t 120 -Z cubic"
control-command = "python -u config/scripts/buffer_size.py"The given example specifies five testcases that use a FIFO Queue and iPerf.
Every testcases file needs to have at least the sections [metadata] and [general].
The [metadata] section contains general human-readable information about the testcases, such as their name, a description, and the name and e-mail address of the author.
The [general] section defines the general testcase and must always be present.
All following sections describe additional testcases.
These testcases inherent and overwrite the values given in the general testcase.
Using the disabled key, a testcase can be deactivated.
When disabling the general testcase, it is no longer executed, but is used only as the base for the other testcases.
In the given example, the general testcase is disabled, but defines the graph-file, the source-command, the sink-command and the number of repetitions.
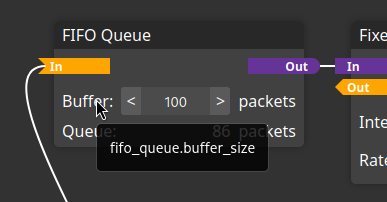
The general testcase is followed by the two simple testcases shallow-buffer and deep-buffer. These testcases set the buffer size of the FIFO Queue module to a low or a high value, respectively. This is done by using the module ID followed by the parameter ID separated by a full stop as the key. To obtain the module ID and parameter ID of a specific parameter, you can hover over the label on the left-hand side of the parameter in the GUI, as shown in the figure below.
Often, experiments should be executed for different values for a specific parameter. While this can be achieved by defining separate testcases as shown above, FlowEmu also allows the user to define a vector of values for a parameter. This is done by using a string that contains a comma separated list of the values in square brackets as the value for a parameter. An example for this is shown in the study testcase.
The previously introduced string notation does not only allow specifying a list of fixed values, but can also contain an arbitrary Python expression. By using a Python list comprehension, a list of values can be generated dynamically. An example for this is shown in the python testcase.
Inside the expression, the repetition variable can be used to make a parameter value dependent on the current repetition number, which goes from zero to the number of repetitions decremented by one.
Many modules rely on a random number generator. To enable fast execution and reproducible results, these random number generators are implemented as pseudo random number generators. Therefore, the sequence of random numbers they produce is determined by a seed. If an experiment is repeated multiple times, these seeds have to be changed as otherwise the result of each experiment is (nearly) identical.
A common way to set the seeds is to derive them from the repetition number. This can be done by using a Python expression and the repetition variable like this:
uncorrelated_loss.seed = "repetition"If multiple modules of the same type are used, care has to be taken how the seeds of the individual modules are set. If two modules use the same seed for the same function, there might be the possibility that the run synchronized. If this behavior is not wanted, one of the seed values has to be modified by mathematical arithmetic.
Finally, there is the scripted testcase.
This testcase overrides the source-command to extend the experiment time to 120 seconds.
More importantly, it defines a control-command to start a Python script on the host that changes the buffer size over time.
As shown in the example above, a control program can be set that is started in parallel with the emulation. The control program can modify parameters of the modules via the MQTT Interface of FlowEmu while the experiment is running. To simplify writing such programs, FlowEmu comes with a Python library. The control script used in the testcase example above is shown below.
from time import sleep, perf_counter
import numpy as np
import flowemu.control as flowemu
flowemuctl = flowemu.Control()
# Get start timestamp
timestamp_start = perf_counter()
# Run experiment
timestamp = timestamp_start
for i in np.linspace(0, 100, 11):
module = "fifo_queue"
parameter = "buffer_size"
# Set FIFO queue buffer size
print(f"[{perf_counter() - timestamp_start}] Set FIFO queue buffer size to {round(i)} packets!")
flowemuctl.setModuleParameter(module, parameter, str(round(i)))
# Increase timestamp
timestamp += 10
# Wait with high precision till timestamp is reached
while True:
diff = timestamp - perf_counter()
if diff < 10**-6:
break
sleep(diff * 0.9)
# Close connection to FlowEmu
flowemuctl.close()It can be seen that the script uses the Control class from the flowemu.control module.
This class creates an MQTT connection in the background and provides an easy way to set a module parameter using the setModuleParameter method.
It also simplifies listening to changes of a statistic value by defining a function and adding the onModuleStatistic decorator to it as shown below.
@flowemuctl.onModuleStatistic("fifo_queue", "queue_length")
def onFifoQueueQueueLength(value: str) -> None:
print(f"Queue length: {round(float(value))} packets")After running an experiment, a folder that contains all results can be found in the results directory.
The folder is named with the name of the testcases as specified in the [metadata] section and the date and time when the experiment was started.
The folder includes the file metadata.json that contains metadata about the testcases and the experiment execution.
Additionally, the folder contains the parameters used for each testcase as a separate JSON file.
For each run of every testcase, several log and output files are created.
The .log file contains all MQTT message that where exchanged during the experiment together with a timestamp in milliseconds with an accuracy of 1/10 millisecond.
These contain the values of all parameters and statistics, so they can be used when processing the results.
Additionally, an .out file is created for every component, which contains the respective command-line output.
Here, every line is also timestamped.
Based on the outputted results, figures can be created.
An example for this can be found in the tools/plot.py script.
The script accepts a .log file from an experiment as a command-line argument and plots the queue length of the first FIFO Queue.
The figure is shown interactively in a window.
This script can be used as a basis for writing your own result processing scripts.