-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
106 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,106 @@ | ||
| +++ | ||
| draft = false | ||
| date = 2024-10-24T22:05:38+08:00 | ||
| title = "以翻译 Kubernetes 文档为例,AI 模型 Fine-Tuning 微调探索" | ||
| description = "以翻译 Kubernetes 文档为例,AI 模型 Fine-Tuning 微调探索" | ||
| slug = "" | ||
| authors = [] | ||
| tags = ["AI", "LLM"] | ||
| categories = ["AI"] | ||
| externalLink = "" | ||
| series = [] | ||
| disableComments = true | ||
| +++ | ||
|
|
||
| 在现在的 `AI` 领域,`Fine-Tuning`(微调)是一种常见且有效的方法,通过对已经训练好的模型进行特定任务的微调,可以使模型在特定场景下表现得更加出色和符合需求。在这篇文章中,我将以 `Kubernetes` 文档的英译中为背景,分享我进行 `Fine-Tuning` 的探索过程。 | ||
|
|
||
| ## Fine-Tuning 的基本过程 | ||
|
|
||
| `Fine-Tuning` 的核心思想是,在一个预训练模型的基础上,使用特定领域的数据进行进一步训练,从而让模型更好地适应该领域。通常,`Fine-Tuning` 包括以下几个步骤: | ||
| - 选择预训练模型:根据任务需求选择合适的预训练模型,例如特定领域模型或者通用的大语言模型(`LLM`)。 | ||
| - 准备数据集:收集并整理与目标任务相关的数据集,为模型微调提供训练样本。 | ||
| - 模型微调:通过在该数据集上进行训练,使模型在特定任务中表现得更好。 | ||
| - 模型评估与优化:评估模型表现,根据需要进行调整。 | ||
| - 输出新模型:微调完成后,保存优化后的模型,供后续任务使用。 | ||
|
|
||
| 在这次实验中,我首先尝试使用专用的翻译模型进行 `Fine-Tuning`,然后进一步尝试以大语言模型(`LLM`)为基础进行 `Fine-Tuning`。 | ||
|
|
||
|
|
||
| ## 基于特定领域模型的 Fine-Tuning | ||
|
|
||
| 由于翻译是一个特定领域,已经存在很多相关的模型,并且这些模型相比于 `LLM` 会更小。因此,我首先选择了 `HuggingFace` 上的 `Helsinki-NLP/opus-mt-en-zh` 模型进行尝试。 | ||
|
|
||
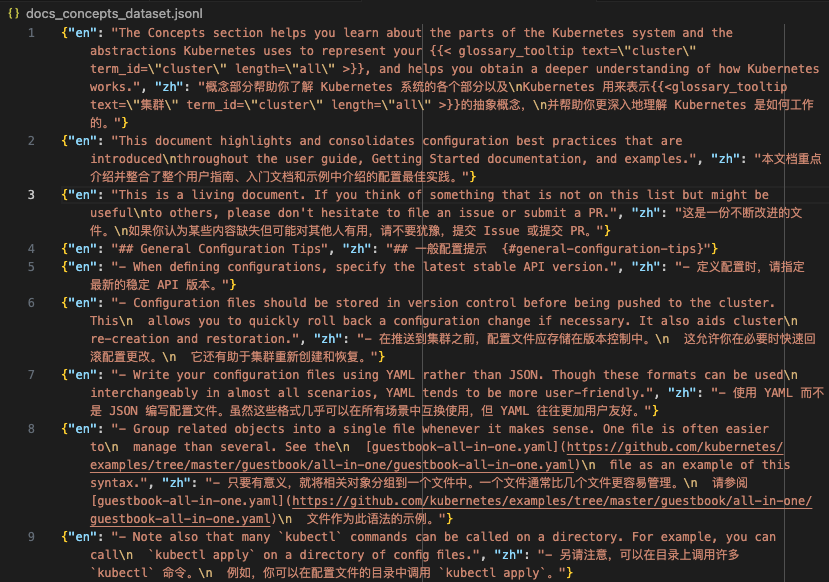
| 数据准备:我的数据集取自 Kubernetes 官方文档,然后整理成了 jsonl 文件,内容如下图所示,en 表示英文原文,zh 表示对应的中文翻译: | ||
|
|
||
|  | ||
|
|
||
|
|
||
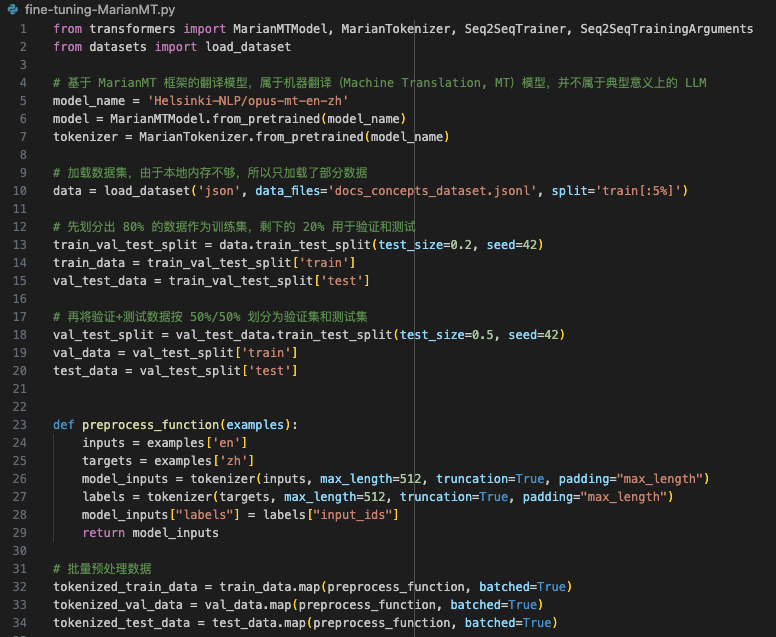
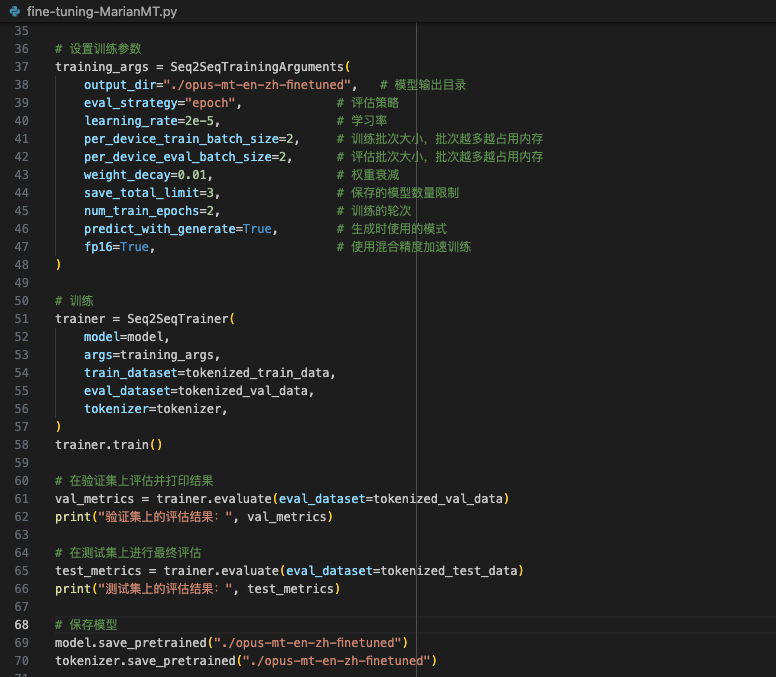
| 代码实现如下: | ||
|
|
||
|  | ||
|
|
||
|  | ||
|
|
||
| 基本过程就是:加载基础模型、加载并划分数据集、数据预处理、设置训练参数然后训练、评估、最后输出微调好的新模型。 | ||
|
|
||
| 由于我本地硬件资源的限制,我只能加载部分数据进行训练,并且降低了训练的批次和轮次,读者可以根据实际情况调整为不同的参数。 | ||
|
|
||
|
|
||
| ## 基于 LLM 的 Fine-Tuning 尝试 | ||
|
|
||
| ### Seq2Seq 和 CausalLM 的区别 | ||
|
|
||
| 上文中使用的翻译领域模型是一种 `Seq2Seq`(序列到序列)模型,它使用的是 `encoder-decoder`(编码-解码)架构,编码器将输入序列编码为一个上下文向量,解码器基于这个上下文向量生成输出序列,翻译的过程就是一个编码解码的过程。 | ||
|
|
||
| 而常见的 `LLM` 则属于 `CausalLM`(因果语言模型),基于自回归方式,仅考虑前面的上下文信息来生成后续词语,其实就是文字接龙。 | ||
|
|
||
| ### LLM Fine-Tuning | ||
|
|
||
| `Fine-Tuning` 的过程基本类似,但是由于 `LLM`(`CausalLM`)与 `Seq2Seq`(`encoder-decoder`)模型并不相同,因此两者在数据集的输入格式、训练方式、评估存在区别。 | ||
|
|
||
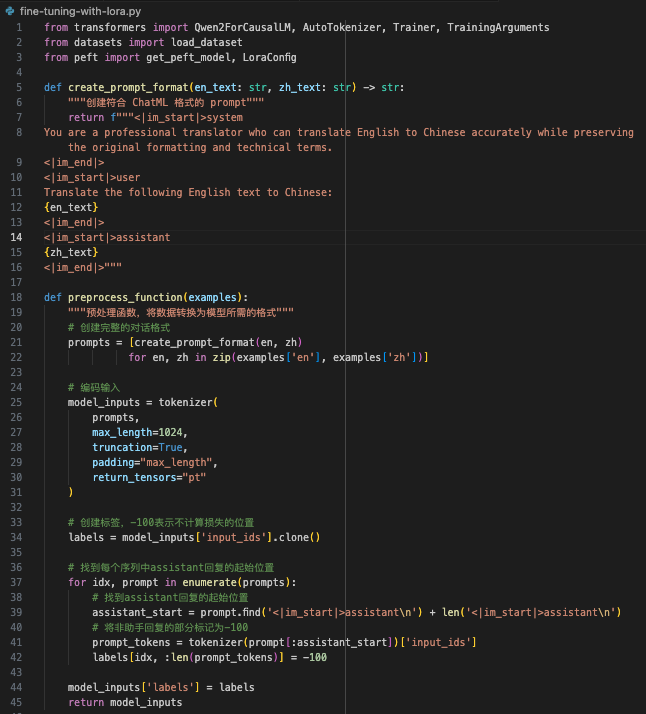
| 比如,使用 `LLM` 进行 `Fine-Tuning` 的时候,需要对输入数据进行额外的 prompt 格式转换: | ||
| ```python | ||
| """<|im_start|>system | ||
| You are a professional translator who can translate English to Chinese accurately while preserving the original formatting and technical terms. | ||
| <|im_end|> | ||
| <|im_start|>user | ||
| Translate the following English text to Chinese: | ||
| {en_text} | ||
| <|im_end|> | ||
| <|im_start|>assistant | ||
| {zh_text} | ||
| <|im_end|>""" | ||
| ``` | ||
| 通过 system 指定背景,user 代表用户,assistant 代表 AI 的回答,把数据集按照上述格式填充,然后再进行训练。 | ||
|
|
||
| ### 使用 LoRA 加速 Fine-Tuning | ||
|
|
||
| 本地训练 `LLM` 会更加消耗资源,即使我只选择了 `Qwen2.5-0.5B` 这个小模型,只加载数据集的部分数据,并且调整训练参数也无法完成 `Fine-Tuning`。因此,我不得不寻求一种资源占用更低、性能更好的方式,而 `LoRA` 就是其中一种。 | ||
|
|
||
| `LoRA` 通过在训练大型模型时引入低秩矩阵分解,只对模型的一部分参数进行 `Fine-Tuning`,其余参数保持不变,从而显著减少内存占用并提高训练效率。 | ||
|
|
||
| 我的代码实现如下: | ||
|
|
||
|  | ||
|
|
||
| 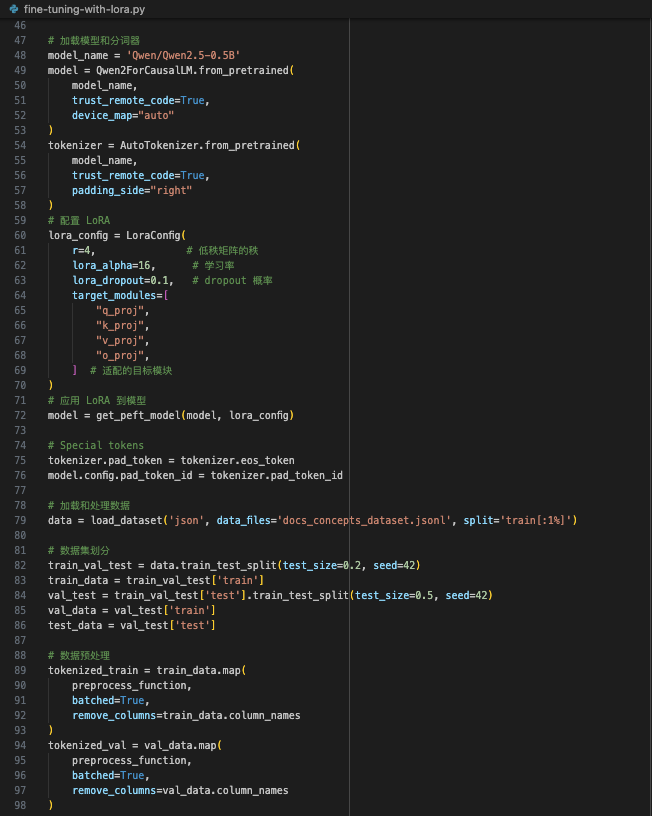 | ||
|
|
||
| 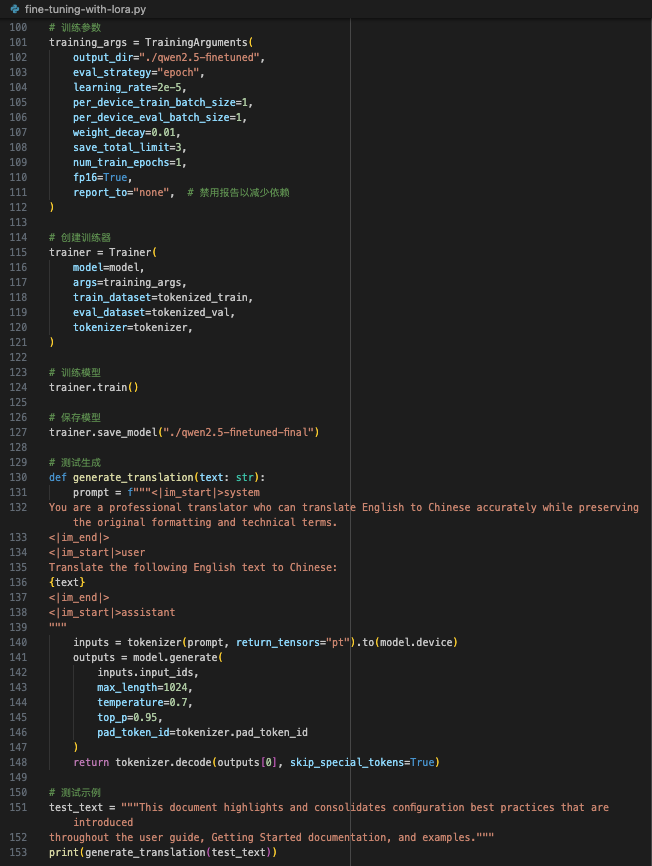 | ||
|
|
||
| 通过 `LoRA` 技术,我得以在有限的硬件资源下完成了 `LLM` 的 `Fine-Tuning`。 | ||
|
|
||
|
|
||
| ## 总结 | ||
|
|
||
| 在这次基于 Kubernetes 文档的翻译实验中,我探索了分别使用特定领域模型和 `LLM` 进行 `Fine-Tuning` 的过程,并通过 `LoRA` 技术有效地提升了 `Fine-Tuning` 的性能。除了 `LoRA` 之外,还有 `Adapter`、`QLoRA`、`DoRA` 等等,它们都属于 `Parameter-Efficient Fine-Tuning`(`PEFT`)的研究范畴。 | ||
|
|
||
|
|
||
| (关注我,无广告,专注技术,不煽动情绪,也欢迎与我交流) | ||
|
|
||
| --- | ||
|
|
||
| 参考资料: | ||
|
|
||
| - *https://huggingface.co/Helsinki-NLP/opus-mt-en-zh* | ||
| - *https://huggingface.co/Qwen/Qwen2.5-0.5B* | ||
| - *https://arxiv.org/html/2408.13296v1* |