-
Notifications
You must be signed in to change notification settings - Fork 1
CRDT 기술공유
간단히 말하자면, 둘은 변경사항을 처리하고 적용하는 기반이 다르다.
OT는 인덱스에 기반한다.
전역적인 순서가 있고, 이 순서에 요소가 있다.
요소를 추가하거나 삭제할 때, 인덱스를 변경한다.
동시에 같은 인덱스에 해당하는 등 인덱스의 변경이 발생하거나, 발생한 이후의 작업의 경우에 충돌 가능성이 높다.
CRDT는 식별자에 기반한다.
각 요소는 고유한 식별자를 갖는다.
충돌 가능성이 적지만, 새로 추가한 요소의 위치가 동일할 경우 이를 결정하는 기준이 필요하다.
이 식별자를 기준으로 변경사항을 적용하는데, 예를들면 다음과 같다.
12345 HELLO
상기와 같은 자료가 있을 때 (각 문자를 요소라 하고, 요소의 식별자는 바로 위의 숫자와 같다.) 다음과 같은 상황이 발생했다고 해보자.
A - HELLO!
B - HEELLO
이때 !에는 6, E에는 3.5등의 고유한 식별자를 부여하고, 이것을 기준으로 변경사항을 처리한다.
변경을 전파함에 따라 A와 B또한 같은 자료를 갖게 되며, 이를 레플리카 라고 한다.
이때 변경 사항 전파는 두가지 방법이 있다. (사실 이것에 따라 CRDT의 유형 또한 나뉜다.)
- State - based
- 전체 상태 (모든 자료)를 공유
- Operation - based
- 수행된 연산(변경된 노드)를 공유
- Delta - based
간단한 동작은 위와 같고, 자세한 내용을 후술하겠다.
CRDT는 다음과 같은 특징을 갖으며, OT와 대비되는 강점이기도 하다.
- 분산 시스템에서 데이터의 일관성을 보장하는 데이터 구조
-
충돌 없는 병합:
- CRDT는 서로 다른 노드에서 발생한 변경 사항을
중앙 서버나 외부 동기화 없이병합할 수 있음 - 병합은 연산이
교환법칙(Commutative),결합법칙(Associative),항등법칙(Idempotent)을 만족하도록 설계돼야 함
- CRDT는 서로 다른 노드에서 발생한 변경 사항을
-
강한 최종 일관성(Strong Eventual Consistency):
- 네트워크가 비동기적이거나 일시적으로 단절되어도, 시간이 지나 모든 복제본(replica)은
동일한 상태로 수렴함
- 네트워크가 비동기적이거나 일시적으로 단절되어도, 시간이 지나 모든 복제본(replica)은
-
분산 친화성:
- 중앙 관리 서버가 없어도 각 노드는 독립적으로 데이터를 수정하고, 동기화 함
- 네트워크 지연이나 연결 단절이 발생해도 동작이 가능, 연결이 복구되면 자동으로 병합을 수행
-
불변 데이터:
- CRDT는 일반적으로 데이터를 변경하지 않으며, 새로 추가하거나 논리적으로 삭제하는 방식으로 작동
- 상기 특성이 병합시 발생하는 데이터 충돌을 방지하는데 일조
-
삽입 (Insert)
- 노드 A와 노드 B 사이에 새 노드를 삽입하는 연산
- 삽입된 노드에는 고유 ID와 논리적 위치값이 할당됨
- 예:
"Heo"에서'l'삽입 →"Helo"
-
삭제 (Delete)
- 노드를 물리적으로 제거하지 않고, **
논리적 삭제 플래그**를 활성화하여 삭제 - 삭제된 노드는 병합 시 여전히 참고되므로 충돌 방지에 활용할 수 있음
- 예:
"Hello"에서'l'삭제 →"Helo"
- 노드를 물리적으로 제거하지 않고, **
-
병합 (Merge)
- 각 노드의 고유 ID와 논리적 위치값을 기준으로 삽입/삭제를 재구성하는 연산
- 동일 위치에 여러 삽입이 발생하면, 타임스탬프등의 순서를 정할 기준이 필요함.
ex) A - Heeeello, B - Heeee
llo result: Heeee
kpllo? or Heeeepkllo?
결국 CRDT는 교환, 결합, 항등법칙을 만족하는 연산으로 강한 최종 일관성을 보장하는 데이터 구조인 것이다.
-
G-Counter: 각 노드에서 값을 증가시킬 수 있음. - 병합: 각 노드의 값을 비교해 최대값을 선택.
- 응용: 분산 시스템에서의 이벤트 수집, 동시 사용자 수 계산.
-
G-Set(Grow-only Set): 항목을 추가만 할 수 있음. -
OR-Set(Observed-Remove Set): 항목을 추가하거나 삭제 가능. 삭제는 논리적으로 처리. - 병합: 각 노드의 추가/삭제 기록을 병합.
-
LWW-Register: 마지막 쓰기가 우선순위를 가짐(Last-Write-Wins). - 병합: 타임스탬프를 기준으로 가장 최근의 값을 선택.
-
RGATreeSplit, RGA, RGA List, etc...이나Logoot같은 리스트 기반 CRDT는 **텍스트 편집**에 주로 사용. - 각 항목에 고유 ID를 부여하여 순서를 유지하며, 삽입/삭제 연산을 동기화.
리스트 기반 CRDT는 **순서가 중요한 데이터**를 동기화 하기에 적합한 유형이다.
영상 편집 또한 편집 결과에 각 영상의 순서가 중요하므로 해당 유형이 적합해 보인다.
또한 이는 텍스트 동시편집과 유사한 부분이 많아 비슷하게 모델링할 수 있어 보인다.
ex) 문자열 내 문자의 순서 == 타임라인 내 동영상의 순서 문자 볼드, 뉘임 == 영상 편집 내용
삭제 충돌을 해결하기 위한 레코드
분산 시스템에서 데이터 동기화는 몇가지 문제가 있다.
- 각 노드에서 동시에 일어난 작업에 대해서는 모든 노드의 물리적 시계를 동기화는것이 의미가 없다.
- 동시에 일어난 작업에 대해서 논리적인 순서 부여가 필요하다.
- 데이터 수신이 전송한 순서대로 이루어지지 않을 수 있다.
{kind=link}
- 서울 / 부산에는 분산된 DB가 실시간으로 동기화 되고 있음.
- 이벤트를 수행하고, 자신이 받은 이벤트를 다른 지역의 DB로 보내주는 형태로 동기화.
- 서울 DB에 1000원 입급 이벤트 발생. 동시에 부산 DB에 1% 이자 지급 이벤트 발생
이를 논리 시계를 사용해 해결해보자.
램포트 시계는 분산 참여자들 사이에서 논리적 시간을 동기화 해주는 시계다. 즉, 절대적인 시간이 어떤지는 관심 대상이 아니다.
램포트 시계는 다음과 같이 이해할 수 있다.
- 각 분산 참여자는 램포트 시계를 가진다.
- 각 분산 참여자는 ID를 가진다. 이 때, ID는 모든 분산 시스템에서 유일해야함.
- 각 램포트 시계는 0으로 초기화 된다.
- 이벤트가 발생할 때 마다 램포트 시계는 1씩 증가한다.
- 분산 참여자가 다른 분산 참여자에게 메세지를 전송할 때, 자신의 램포트 시계를 넣어서 보내준다.
- 분산 참여자가 메세지를 받았을 때, 자신의 램포트 시계를 다음과 같이 업데이트 한다.
- C(메세지) < C(자신) → C(자신) + 1
- C(메세지) = C(자신)
- ID(메세지) < ID(자신) → 무시함
- ID(메세지) = ID(자신) → 이런 경우는 없음
- ID(메세지) > ID(자신) → C(메세지) + 1로 업데이트 함.
- C(메세지) > C(자신) → C(메세지) + 1
(2단계 커밋 프로토콜과 유사한 방법)
!https://blog.kakaocdn.net/dn/eSQd9Y/btsFRDDcbza/EA70imsufzHaSPfbuRhNs0/img.png
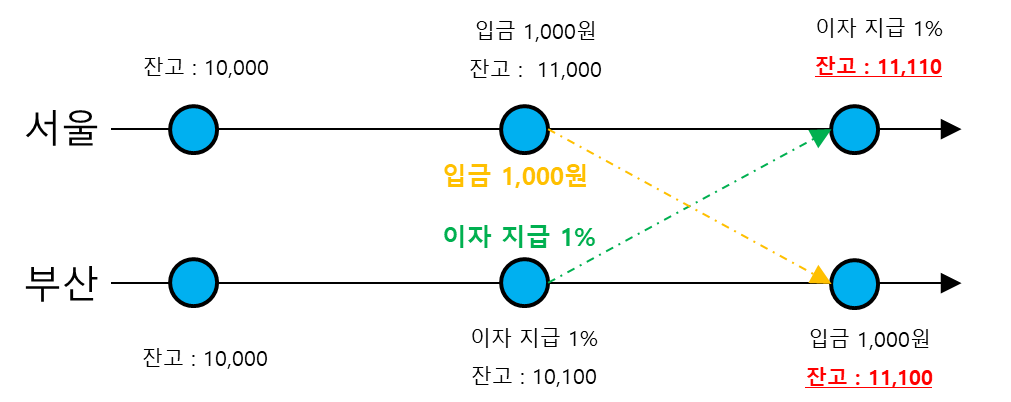{kind=link}
- DB를 업데이트 해야 할 작업이 생기면, 자신과 다른 지점에 통지
- 업데이트 할 작업을 다른 지점에서 수신하면
- 해당 작업을 일단 우선순위 큐에 저장 (우선순위는 램포트 시간만 고려)
- 해당 작업이 우선순위 큐의 가장 앞에 있는 경우에만 회신한다.
- 업데이트 할 일에 대한 수신 확인 메세지를 받으면, 해당 작업이 다른 지점에서도 확인되었음을 표시한다.
- 확인된 작업은 큐에서 가장 첫 번째 자리에서 제거하고, 해당 작업을 수행한다.
위 제한 사항에서는 이벤트가 항상 순서대로 처리된다.
!https://blog.kakaocdn.net/dn/mXwnG/btsFPFCyvJL/Dk0GN8DHQMoOhjUq6oMywk/img.png
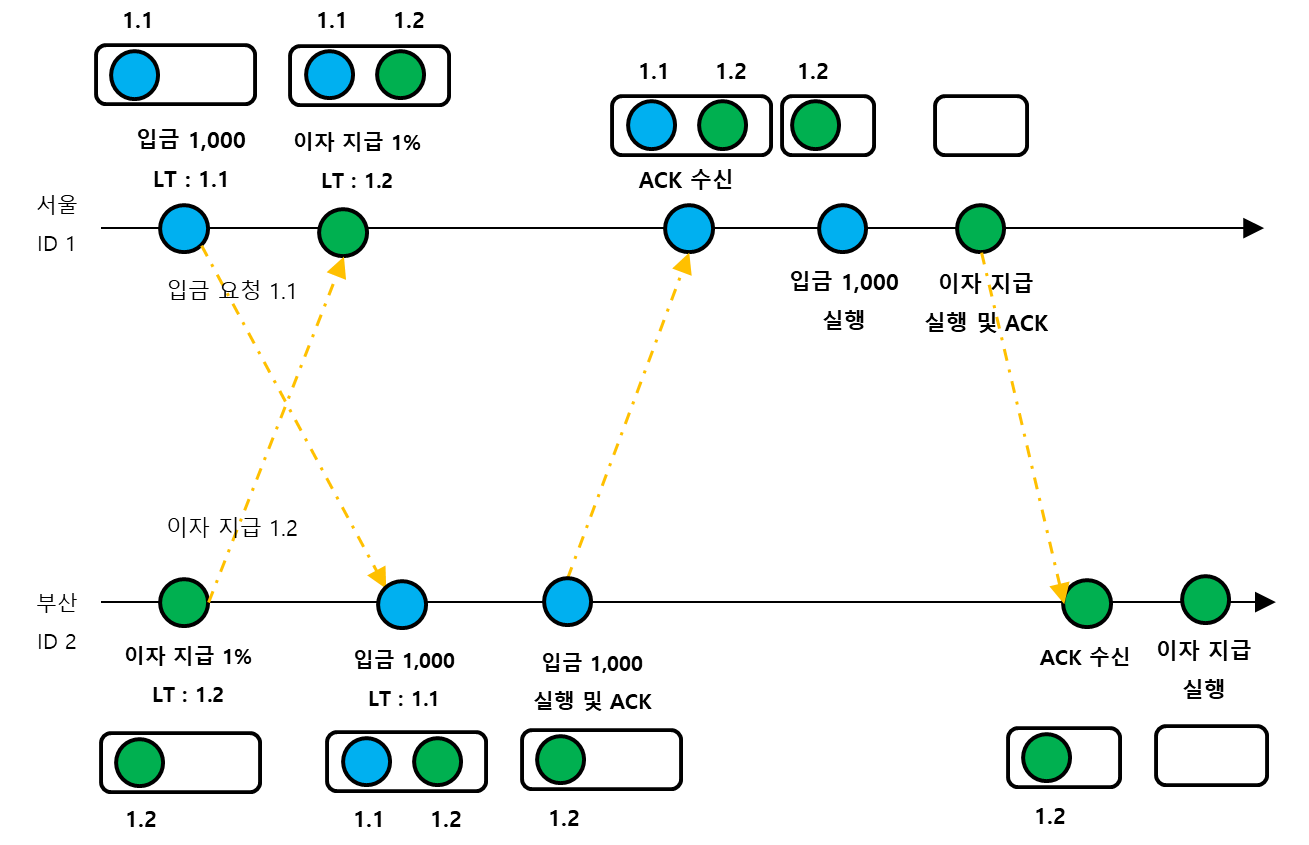{kind=link}
- 이벤트 발생 시점의 램포트 시간을 LT로 표현했다.
- 우선순위 큐는 램포트 시간을 기준으로 배열한다.
- 램포트 시간이 빠른 입금 요청이 먼저 우선순위 큐의 앞으로 가게 되어 ACK되고 먼저 실행된다.
이 Case가 시사하는 바는 램포트 시간을 추가하면, 분산 시스템의 참여자들의 시간을 논리적으로 동기화해서 발생 순서대로 처리할 수 있다는 것이다. 그리고 그 결과 각 분산 참여자는 Consistency를 가지게 된다.
→ 중요한 부분은 메세지를 보내기 전에 기록하고 합의가 완료되면 작업이 진행된다는 점
CRDT는 모든 문자 하나 하나마다 고유한 id를 부여한다.
(이러한 id는 단지 개념에 대한 예시일뿐 정해진 형태는 아님)
Node A
char -> H e l o
index -> 0a 1a 2a 3a
Node B
char -> H e l o
index -> 0a 1a 2a 3a
이때 Node A와 Node B에서 다음과 같이 concurrent하게 edit를 했다고 가정하자.
Node A
char -> H e l l o
index -> 0a 1a 2a 4a 3a
Node B
char -> H e l o !
index -> 0a 1a 2a 3a 4b
이런 경우 네트워크 레이어에 발행되는 이벤트는 다음과 같다.
Node A
'l'이라는 캐릭터를 4a라는 id로 2a 오른쪽에 넣어줘.
Node B
'!'라는 캐릭터를 4b라는 id로 3a 오른쪽에 넣어줘.
이 이벤트는 같은 CRDT를 공유하는 모든 유저에게 발행된다.
만약 다음과 같이 정확히 같은 위치에 동시에 이벤트가 발행되면 어떻게 처리해야 할까?
Node A
char -> a b c
index -> 0a 1a 2a
Node B
char -> a b c
index -> 0a 1a 2a
Node A에서는 3a를 0a 다음에 넣고, 4a를 3a 다음에 넣는 동시에
Node B에서는 3b를 0a 다음에 넣고, 4b를 3b 다음에 넣도록 수정해보자.
Node A
char -> a x y b c
index -> 0a 3a 4a 1a 2a
Node B
char -> a p q b c
index -> 0a 3b 4b 1a 2a
이런 경우 다음과 같은 이벤트가 발행된다.
Node A
'x'라는 캐릭터를 3a라는 id로 0a 오른쪽에 넣어줘.
'y'라는 캐릭터를 4a라는 id로 3a 오른쪽에 넣어줘.
Node B
'p'라는 캐릭터를 3b라는 id로 0a 오른쪽에 넣어줘.
'q'라는 캐릭터를 4b라는 id로 3b 오른쪽에 넣어줘.
이때 한쪽 Node에서의 작업 처리는 간단하게 가능하다.
예를 들어 위의 Node B에서 발행한 이벤트를 Node A에서는 아래와 같이 conflict없이 처리된다.
Node A
char -> a p q x y b c
index -> 0a 3b 4b 3a 4a 1a 2a
하지만 문제는 다른 Node에서의 작업 처리 방법이다. Node B에 naive한 방식으로 Node A에서 발행한 이벤트를 바로 처리하면 다음과 같이 될겁니다.
Node B
char -> a x y p q b c != a p q x y b c (Node A)
index -> 0a 3a 4a 3b 4b 1a 2a
위와 같이 처리되면 Node끼리 서로 다른 상태를 가지게 된다.
이를 해결하기 위해 다음과 같은 조건을 추가해보자.
발행된 이벤트의 id보다 작거나 같은 id가 이미 존재하면 전부 건너 뛰면서.
이 조건이 추가되면 3a라는 id는 Node B에 존재하는 3b, 4b는 3a보다 작거나 같으므로 건너뛰고 1a보다는 크니까(크면 나중에 발행된 이벤트라는 뜻이므로) 최종적으로 다음 형태를 가지게 된다.
Node B
char -> a p q x y b c
index -> 0a 3b 4b 3a 4a 1a 2a
위와 같은 방식으로 CRDT에서는 distributed system에서 conflict-free한 형태를 가질 수 있게 된다.
그러나 이벤트가 이미 발생한 이벤트에 의존적이고, 네트워크의 특성인 도착 순서를 보장할 수 없음을 고려해보자.
메시지의 전후관계 뿐만 아니라 인과관계도 고려
표현: VCi = (Px, Py, Pz) ( VC = Vector Clock의 약자 이며 i는 프로세스, 노드의 이름(숫자) )
동작
- 어떤 Process가 다른 Process에게 메시지 를 보낼 경우 Vector 값 중 자신에게 해당 되는 부분을 1증가 시키고 메시지와 같이 전송
- 수신한 Process는 자신의 Vector와 비교하 여 일관성에 문제가 없을 경우 Vector 업 데이트
- 만약 수신한 메시지의 Vector 일관성이 없 다면 대기시키고, 일관성이 일치하는 다른 Vector를 가진 메시지를 Update 수행
(상기한 2커밋 프로토콜과 유사)
!https://blog.kakaocdn.net/dn/lzwNP/btsCk3GtOaz/49FI7OYV1qvHhFf7tooPck/img.png
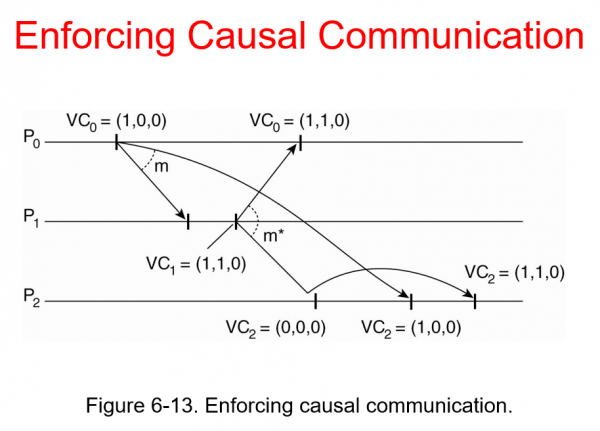{kind=link}
P0에서 m이라는 메시지를 보내고있으며 P1의 m*는 m에 의해서 생성된 메시지 (인과관계가 존재)
모든 VC는 처음에 VC=(0,0,0)으로 시작하여 첫번째 자리의 0은 P0의 이벤트 발생수, 두번째 0은 P1의 이벤트 발생수 세번째, 0은 P2의 이벤트 발생수를 말한다.
VC0에서 (1,0,0) 인 경우 P0에서 발생되었기 때문에 첫번째 자리에 +1이 카운팅 된다. P0에서 m메시지를 보내는 이벤트를 수행하였다.
P1에서 수신했을때는 (1,0,0) 이지만 m*가 생성되었기 때문에 VC1(1,1,0)으로 이번에는 두번째가 카운트 된다.
하지만 무엇이 문제인가? P2가 문제가 되는 상황이다. P2에서는 m1이 먼저 수신되는 것이 아니라 m가 먼저 수신되기에 일관성이 없다. 하지만 VC2= (0,0,0) 상태가 되는 이유가 무엇일까? 원래는 P1에서 전달받았기에 (0,1,0)이어야 한다. 하지만 일관성이 없다고 판단하고 m를 홀드시킨다. 홀드시킨 후 m이 오면 이후에 m를 처리한다. 이후 VC2는 m을 받고 (1,0,0) 이 되고 m를 받았기에 m를 처리한다. 따라서 VC2=(1,1,0)이 된다. 정확하게 P0 / P1 / P2 가 정확하게 (1,1,0) 으로 동기되게 된다.