Regularisation
Intro to regularisation in cs231n
Article by analyticsvidhya-
- Regularization is a technique which makes slight modifications to the learning algorithm such that the model generalizes better. This in turn improves the model’s performance on the unseen data as well.
- Assume that our regularization coefficient is so high that some of the weight matrices are nearly equal to zero.
- Large coeff - linear line - all weights nearly equal. Underfitting.
- Small coeff - curly line - biased weights - overfitting.
- Cost function = Loss (say, binary cross entropy) + Regularization term
-
L2 -
-
L1 -
- In this, we penalize the absolute value of the weights. Unlike L2, the weights may be reduced to zero here. Hence, it is very useful when we are trying to compress our model. Otherwise, we usually prefer L2 over
- Dropout
- Data Augmentation - there are a few ways of increasing the size of the training data – rotating the image, flipping, scaling, shifting, etc.
- Early stopping - Early stopping is a kind of cross-validation strategy where we keep one part of the training set as the validation set. When we see that the performance on the validation set is getting worse, we immediately stop the training on the model.
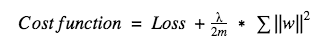
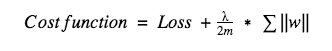
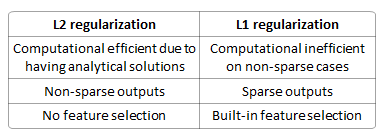
differences-between-l1-and-l2-as-loss-function-and-regularization
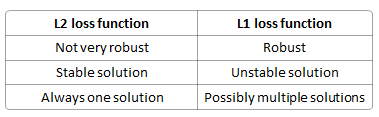
Regularization loss???