LHS Registers Part 1 - DotOp Hoisting and SMEM-RF Copy Lowering #18
Conversation
|
Addressed all comments in the original PR that are relevant to part 1 in this PR instead. |
| @@ -11,6 +11,8 @@ | |||
| import pytest | |||
| import torch | |||
| import os | |||
| os.environ['TRITON_ALWAYS_COMPILE'] = '1' | |||
| os.environ['MLIR_ENABLE_DUMP'] = '1' | |||
There was a problem hiding this comment.
looks like these were leftover from debugging
04ed621
to
b7e2df0
Compare
3596dc5
to
10d3305
Compare
|
Ops, seems that updates we have to maintain the Triton integration will cause PR diffs to break because of force-updates. We might need to figure out a better way to handle this as we didn't intend for this repo to accept incoming PRs. Apologies for this, but you will need to rebase again for the diff to include the proper changes. |
1b95c9a
to
942dad4
Compare
|
@Moerafaat np - I've reapplied my changes on the new main |
third_party/nvidia/lib/TritonNVIDIAGPUToLLVM/ConvertLayoutOpToLLVM.cpp
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
nb. I have not reviewed OptimizeDotOperands.cpp, @ThomasRaoux should probably review that part once you put up a PR against the triton repo.
First of all, hats off if you've managed to fix SharedToDotOperand for kWidth != 2! It was an absolute madness of indices.
Now, @Jokeren is working on completely removing this devilish path in favour of the cleaner and more correct conversion via linear layouts. I think a more long-term solution here would be to implement linear layout support for DotOperand for Hopper, but we can do this in a follow-up PR.
| // To unify the ordering conventions would potentially require touching | ||
| // `ConvertLayoutOpToLLVM.cpp`, `ElementwiseOpToLLVM.cpp`, `MMAv2.cpp`, |
There was a problem hiding this comment.
This is going to be fixed (at last!) in triton-lang#4951. Hopefully it'll get merged today, tomorrow at latest.
| if (isHopperWidthChange) { | ||
| vecWidth = 4 / mmaElemBytes; | ||
| } else { | ||
| vecWidth = 4 / elemBytes; | ||
| } |
There was a problem hiding this comment.
Do you mean vecWidth = kWidth here? This way, it would work for kWidth > 4.
There was a problem hiding this comment.
I just left this comment below (#18 (comment)) which I think also applies to this question.
In what case would we have kWidth > 4 though? For Ampere and Hopper we should have 4 as the maximum right (with int8/fp8 dtype)
| // width-changing casting is done later in DotOp Layout... then, in the case of | ||
| // Hopper, the number of bytes held by each thread after loading will no longer | ||
| // be 32B. Hence this flag is required to stipulate different logic. | ||
| bool isHopperWidthChange = isHopper && (mmaElemBytes != elemBytes); |
There was a problem hiding this comment.
You're right, and it makes me wonder now why this was working for Ampere before without this flag.
I'll inspect this code a bit more and come up with an explanation.
There was a problem hiding this comment.
The answer is that it just didn't work before. That's one of the reasons why we started migrating everything to Linear Layouts, and it's that code written manually has very subtle bugs like the ones you fixed in this PR :)
There was a problem hiding this comment.
Update - I was testing int8 -> f16 for Ampere and was surprised at first to find that it was working correctly.
I've now come up with an explanation. You probably already know most of the following, but I'd just like to confirm we're on the same page:
If I have AxB where A is int8 and B is f16, with A cast to f16 before MMA, AccelerateMatmul.cpp will compute kWidth for both operands as 4. This is due to the logic in computeOrigBitWidth, which calculates the kWidth using the bitwidth of the smallest element along the dot-op chain. In my case this smallest element is int8, so kWidth = 32 / 8 = 4.
But the eventual layout right before MMA is f16, so the kWidth should be 2. So, it seems at first glance that with kWidth = 4, the results should be wrong. For example, for operand A, f16 layout expects thread 0 to hold elements
(0, {0, 1}), (8, {0, 1}), (0, {8, 9}), (8, {8, 9}) # (m_index, {k_indices...})
...but in reality, we load it with kWidth = 4, meaning
(0, {0, 1, 2, 3}), (8, {0, 1, 2, 3}), (0, {8, 9, 10, 11}), (8, {8, 9, 10, 11})
(I've attached Ampere dotOp layouts for int8 and f16 at the end)
So each "rep" of A here doesn't actually mean a "rep" of the actual f16 MMA instruction, but instead corresponds to 2 reps.
OTOH, B is also loaded with kWidth = 4, but with vecWidth = 2, so the first rep of B is loaded in this order:
(n_offset=0, k_offset={0, 1}), (n_offset=0, k_offset={8, 9})
and the second rep...
(n_offset=0, k_offset={2, 3}), (n_offset=0, k_offset={10, 11})
To match the ordering of elements in A and B, the lowering of int8 -> f16 will reorder the values of A, so that every 16 values of A can be split into 2x 8 values, i.e. 2 reps:
(m_offset=0, k_offset={0, 1}), (8, {0, 1}), (0, {8, 9}), (8, {8, 9})
(m_offset=0, k_offset={2, 3}), (8, {2, 3}), (0, {10, 11}), (8, {10, 11})
I think the key observation here was that the element ordering along K doesn't have to match what the PTX doc prescribes, as long as it's consistent between A and B.
To conclude, the logic here works for Ampere thanks to reorderValues (which has logic for 8b <> 16b and 16b <> 32b). OTOH, for WGMMA, I'd have to previously set kWidth = 2 and have special logic here to load the correct number of values; this is because operand B is always in shmem and doesn't have the kWidth/vecWidth logic above for Ampere's B.
My thought is that the reordering trick might allow for more vectorization and so might actually be worth implementing for Hopper. For this PR though, things look to be functionally correct for both Hopper and Ampere, so should I just leave the logic here as-is for now? (or unless there are other things, which I'm not aware of, that didn't work for Ampere that my Hopper fix here could extend to?)
Operand A layout for mma.m16n8k16 with int8:
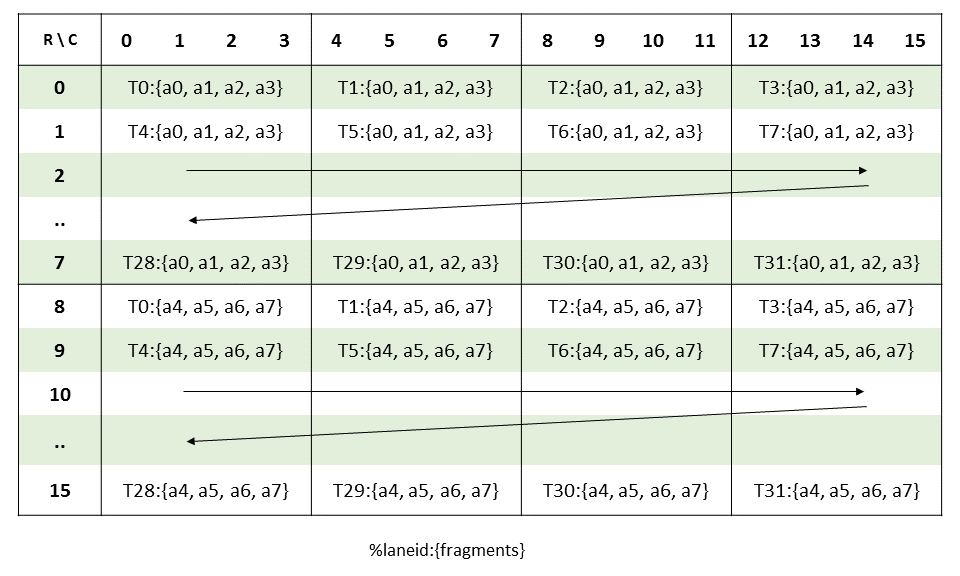
Operand A layout for mma.m16n8k16 with f16/bf16:

There was a problem hiding this comment.
That's a pretty neat analysis!
The issue here is that I pretty much hit these bugs when doing fp4 x bf16, so, following the logic for fp8 x bf16, I chose kWidth=8, but then everything breaks as these computations break with kWidth > 4. Using kWidth=1 and kWidth=4 I was hitting a similar bug as well.
In general, the issue with most of these computations is that they are done in terms of element sizes (which is a tensor-level concept) instead of kWidth, which is a layout-level concept. For example, the same vectorisation optimisations could be done by looking at the kWidth themselves. cc @Jokeren who is trying to clean-up all this.
That being said, we have what we have, so our current attack route to clean all this mess is using LinearLayouts. The idea moving forward is to implement LinearLayout conversions for all the layouts we have. LinearLayouts are easy to prove to be correct, and all these optimisations can be implemented rather cleanly at a layout level.
With all this I want to say that it's probably fine for this code not to support Hopper with kWidth > 4, as we are aiming to delete it anyway in favour of our LinearLayout path.
| // matK (k-index of the "warp matrix") | ||
| // quadK (k-index of the "quad" in the core matrix) | ||
| // quadM (m-index of the "quad" in the core matrix) | ||
| // vecIdx (index of the element in the quad; this is always along the k-dim) |
There was a problem hiding this comment.
Don't you need to support kWidth in this file? Or are you expecting that kWidth = 4 / elemSize at this stage? If so, could you add an assert?
Note that this needn't be the case, and we could have a larger kWidth, and have this code emit kWidth / (4 / elemSize) wgmma ops.
There was a problem hiding this comment.
well, I guess that it's just the lhs that supports funny kWidths, so at this stage the kWidth should agree. It would be good to assert that though.
| int mmaInstrM = 16, mmaInstrN = 8, mmaInstrK = 4 * 64 / mmaBitwidth; | ||
| int matShapeM = 8, matShapeN = 8, matShapeK = 2 * 64 / mmaBitwidth; |
There was a problem hiding this comment.
Probably write 2 * kWidth rather than 64 / mmaBitwidth for both Hopper and Ampere, as this is in both cases the number of elements along K.
There was a problem hiding this comment.
At this point I believe kWidth may not equal 32 / mmaBitwidth for Ampere.
In the example in my comment above, operand B will have dtype = f16 but kWidth = 4. I think that in this case, matShapeK should be calculated based on the dtype bitwidth, so that the element ordering is correct.
| int bitwidth, | ||
| int opIdx) const { | ||
| assert(isAmpere() || isHopper()); | ||
| auto rank = shape.size(); | ||
| auto warpsPerCTA = getWarpsPerCTA(); | ||
| SmallVector<int> shapePerWarp = {1, 16, 8, 4 * 64 / bitwidth}; |
There was a problem hiding this comment.
What about the n value here in Hopper?
There was a problem hiding this comment.
Ok, after having a thought about this, I guess that in all these places that depend on instrN, it's fine to leave n = 8, as the n pattern repeats with period 8 for the different tile sizes.
It would be good to leave a note somewhere in the code and refer to that note in all the places where we use this "trick" (here, in the SharedEncodingAttr, in the shared to dot operand mma, etc).
There was a problem hiding this comment.
For Hopper actually opIdx should always be 0 since WGMMA doesn't support operand B in registers, and so we shouldn't ever use the n value.
I can add an assert here for opIdx == 0
There was a problem hiding this comment.
right! Adding an assert would be great.
|
Also, could you |
|
@ggengnv do you know roughly when will you be able to rebase this on top of main and address the review? I think we would like to incorporate this work upstream sooner than later. If you are busy, I can help with the rebasing and addressing the review. |
|
@lezcano Hey, sorry for taking a bit on this. I was busy last week but I'm rebasing this now. Aiming to get this done soon today; will keep you updated. |
|
PR transferred to triton-lang: triton-lang#5003 |
da8895b
to
c8f89a6
Compare
|
merged into upstream triton |
(Part 2: #19)
Part 1 of "WGMMA with LHS operand in registers" feature.
Hopper has two kinds of WGMMAs, "SS" (both operands in shmem) and "RS" (LHS operand A in registers).
In cases where we apply elementwise operations on A before WGMMA, Triton previously will copy A from global memory (GMEM) into registers (RF), perform the elementwise ops, and then copy to shared memory (SMEM) to perform SS WGMMA.
This PR adds an optimization for the case above to use RS GEMM. This requires the following changes:
Being without pipelining, this PR is not expected to see perf gains. Pipelining for MMAv3 operand in registers is added in Part 2.