Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
GRU is a type of Recurrent Neural Network(RNN). It accepts inputs as x_t and updates its hidden state h_t for each timestep t according to the following formula.
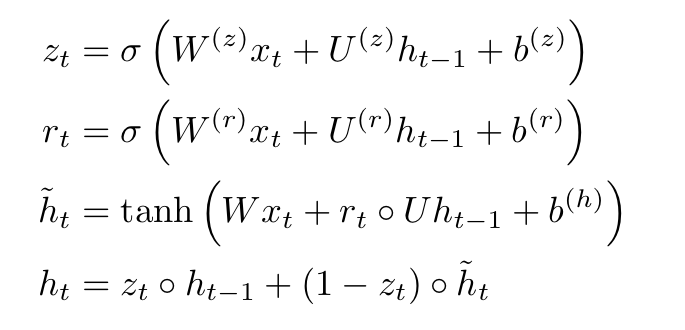
x_t is the input vector at timestep t. W, U, and b are learnable parameters. With these values, we calculate z_t, r_t, h_t tilde, and h_t, which are all vectors. A single timestep operation of a GRU can be summarized as h_t = GRU(x_t, h_{t-1}).
Now let us analyze the above mechanism in terms of z_t and r_t with a bit of intuition. Since both are an output of the sigmoid function, they are values between 0 and 1. The intermediate variable r_t, called the reset gate vector, determines how much to retain the previous hidden state. On the other hand variable z_t, called the update gate vector, determines the ratio with which to mix the previous hidden state and the current hidden memory.
The importance of QA(Question Answering) problems in NLP:
Most, if not all, tasks in natural language processing can be cast as a question answering problem

Dynamic Memory Network (DMN):
... a neural network based framework for general question answering tasks that is trained using raw input-question-answer triplets.
The DMN first computes a representation for all inputs and the question. The question representation then triggers an iterative process that searches the inputs and retrieves relevant facts. The DMN memory module then reasons over retrieved facts and provides a vector representation of all relevant information to an answer module which generates the answer.
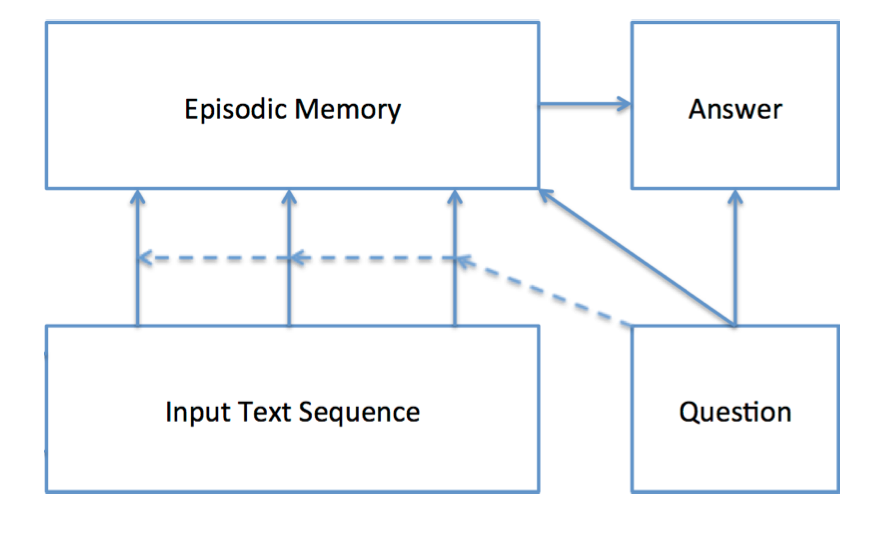
.png)
The forward propagation algorithm is described below for each module.
T_C개의 input sentence를 받아서 truth representation vector로 변환
- 문장의 단어를 embedded vector로 변환 (pretrained GloVe)
- 각 문장 뒤에 end-of-sentence 토큰을 붙여 하나로 concatenate
- h_t = GRU(w_t, h_{t-1})
- end-of-sentence 토큰을 만날 때의 h_t를 c_i라고 부름
=> c_1, c_2, cdots, c_{T_c}: T_c개의 벡터를 반환
T_Q개의 단어로 이루어져 있는 질문을 받아서 question representation vector로 변환
- Input Module과 같은 embedding layer를 거쳐 embedding vector로 변환
- q_t = GRU(w_t, q_{t-1})
=> 마지막 q_{T_Q}번째 hidden state 벡터를 반환
i = 0
m_0 = q
while not end_condition:
for t in range(T_C+1, 1):
1. calculate feature vector z(c_t, m^{i-1}, q) where
z(c, m, q) = [c, m, q, c*m, c*q, |c-m|, |c-q|, c*W*m, c*W*q]
2. calculate the degree of attention, g_t^i. This is a two-layer fully connected network forward pass.
3. h_t^i = g_t^i * GRU(c_t, h_{t-1}^i) + (1-g_t^i) * h_{t-1}^i
4. e^i = h_{T_C}^i
5. m^i = GRU(e^i i, m^{i-1})
6. i = i + 1
=> 마지막 m^{T_M} hidden state 벡터를 반환
while argmax(y_t) is not end_of_sequence: 1. a_t = GRU(y_{t-1}.q, a_{t-1})
2. y_t = softmax(W * a_t)
The answer generated in the t'th timestep is argmax(y_t).
The facebook bAbI dataset provides training examples that each contains several information sentences, a question sentence, the answer to the question, and which information was the most important one in answering the question. With such label, we first train the episodic memory module that calculates the degree of attention, g_t^i. After the attention is trained reasonably, we add up the loss functions for the attention and answering part and continue training.
DMN models are trained separately for each question type (information reasoning, sentiment analysis, part-of-speech tagging, ...). It achieved SOTA (at that time) for most criteria. Refer to the paper for details.
주어진 문장이 매우 많을 때는 잘 동작하지 않는다고 한다. 아무래도 벡터 하나로 질문과 관련된 모든 정보를 요약하려 하기 때문인듯 싶다. 가령 이 모델을 책을 읽혀서 시험문제를 풀게 한다던가 하는 건 어려울 것 같다. Short-term memory가 유용한 분야에 써보던가, 아니면 short-term memory가 long-term memory로 넘어가는 메커니즘을 응용해서 모델을 만들어볼 수 있지 않을까?