SRCNN: Image Super Resolution Using Deep Convolutional Networks
Youtube, TensorFlow KR 논문읽기 모임
- SISR(Single-Image Super-Resolution) 문제에 최초로 딥러닝을 적용하였다.
- 이전의 State-of-art 방법이었던 Sparse-coding Based SR이 CNN의 관점으로도 해석할 수 있음을 보였다.
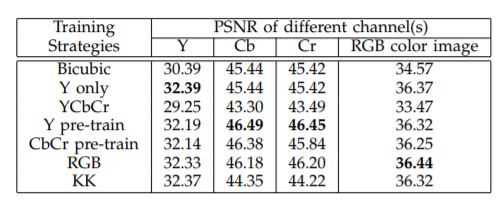
- 다양한 색상 채널, Kernel Size에 대해 실험했으며 색상 채널은 RGB일때 가장 좋게, Kernel Size는 Performance와 Time이 Compromise하는 결과를 보였다.
PSNR: Peak Signal-to-noise ratio
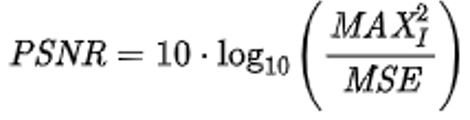
통상적으로 신호 대 잡음 비의 의미를 가지고 있지만, Image Restoration에서는 다른 의미를 가진다. 분모 부분의 MSE가 {원본 이미지 - 복원 이미지}의 L2 Loss로 들어가며, Loss(분모)가 작으면 PSNR이 커지기 때문에 PSNR은 Image Restoration의 품질을 측정하는 척도 중 하나이다.
Bicubic Interpolation
Image Upsampling(이미지 사이즈 키우기)를 할 때 쓰이는 방법 중 하나. Wikipedia
SRCNN, VDSR 등 pre-upsampling 기반의 SISR 기법에서 주로 사용되었으나, Interpolation은 그 비용이 적지 않고, 기존의 이미지에 대한 추가적인 정보를 전혀 제공하지 않는다는 지적 때문에 ESPCN 등의 post-upsampling SISR 기법들이 나오기도 하였다.
Sparse Coding
참고 - Github TesorFlow Code(https://github.com/tegg89/SRCNN-Tensorflow)
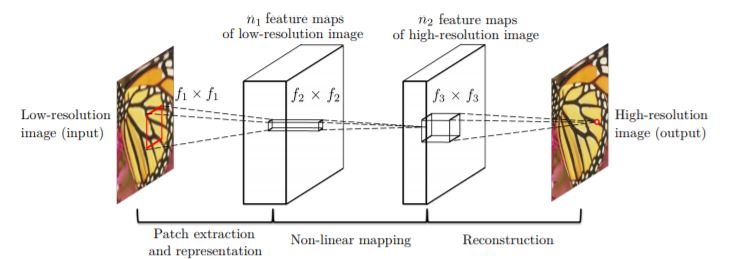
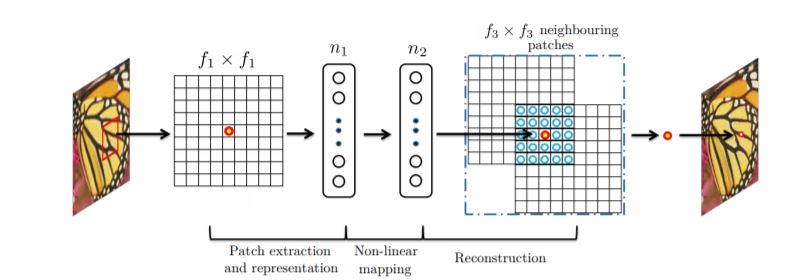
1. Patch Extraction Input Image를 같은 Size(논문에서는 33 * 33)의 Patch로 조각낸다.
2. Patch Representation Conv1 - Relu1 Layer를 거쳐 두께 n_1의 feature map을 생성한다.
3. Non-linear Mapping Conv2 - Relu2 Layer를 거쳐 두께 n_2의 feature map을 생성하며, 이는 모델에 nonlinearity를 모델에 부여하는 역할을 한다.
4. Reconstruction Conv3 Layer를 거쳐 Restored Image를 생성한다.
Loss Function: 
실제로 model을 evaluate할 때는 각각의 patch를 merge하여 하나의 이미지로 합치는 과정이 수반된다(따라서 Zero Padding을 하지 않을 경우 output이 HR이미지에서 테두리를 잘라낸 형태가 된다).
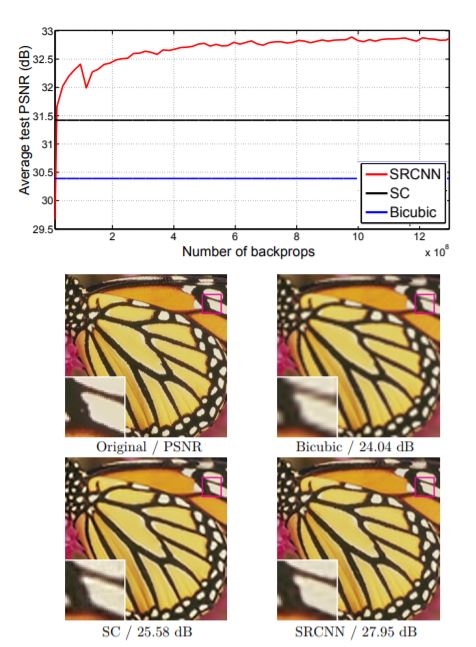
Sparse Coding Based SR 논문 arxiv을 정독하기 어려운 관계로, Sparse Coding 자체와 SRCNN을 비교해본다.
(https://bskyvision.com/177)
에서 설명한 Sparse coding(DMOS를 예측하는 방법)과 SRCNN을 비교한다.
- Representation 은 새로운 Image의 특성을 뽑아내서 새로운 열벡터를 만드는 것에 해당한다.
- Non-linear mapping 은 각 atom에 해당하는 DMOS 값을 대응시키는 과정에 해당한다.
- Reconstruction은 계수들을 DMOS값에 각각 곱해서 최종 결과(Prediction)을 만들어내는 것에 해당한다.
Super Resolution 문제에서 Confidence Map을 어떻게 그릴 수 있을까?