Demo
demo of functionality upto commit 8587ccf154fa28732e08477b5e9639abd237688a
- Deploying Spark Oracle
- Configuring Spark Oracle
- The Spark Context
- Catalog integration
- Query Pushdown
- Parallel Data Movement
- Insert/Delete on Oracle tables
- Programmatic Example operating on Oracle Data
- Language Integration
The spark oracle zip file has the spark-oracle and oracle jdbc jars :
 This zip file can be unzipped into any spark deployment.
You can build the zip file by issuing:
This zip file can be unzipped into any spark deployment.
You can build the zip file by issuing: sbt clean compile test;sbt -DaddOraJars=true universal:packageBin
In order to enable the Spark Oracle catalog integration and pushdown functionality
add the following to your spark configuration
# Oracle Catalog
# enable Spark Oracle extensions
spark.sql.extensions=org.apache.spark.sql.oracle.SparkSessionExtensions
spark.kryo.registrator=org.apache.spark.sql.connector.catalog.oracle.OraKryoRegistrator
# enable the Oracle Catalog integration
spark.sql.catalog.oracle=org.apache.spark.sql.connector.catalog.oracle.OracleCatalog
# oracle sql logging and jdbc fetchsize
spark.sql.catalog.oracle.log_and_time_sql.enabled=true
spark.sql.catalog.oracle.log_and_time_sql.log_level=info
spark.sql.catalog.oracle.fetchSize=5000
# Query pushdown
spark.sql.oracle.enable.pushdown=true
# Parallelize data movement.
spark.sql.oracle.enable.querysplitting=false
spark.sql.oracle.querysplit.target=1Mb
# Configure jdbc connection information
# some example below
# this demo is for jdbc:oracle:thin:@slcaa334:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com
# tpcds scale1 instance
spark.sql.catalog.oracle.url=jdbc:oracle:thin:@slcaa334:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com
spark.sql.catalog.oracle.user=tpcds
spark.sql.catalog.oracle.password=tpcds
# Example config for an ADW instance
#spark.sql.catalog.oracle.authMethod=ORACLE_WALLET
#spark.sql.catalog.oracle.url=jdbc:oracle:thin:@mammoth_medium
#spark.sql.catalog.oracle.user=tpcds
#spark.sql.catalog.oracle.password=Performance_1234
#spark.sql.catalog.oracle.net.tns_admin=/Users/hbutani/oracle/wallet_mammoth
#spark.sql.catalog.oracle.oci_credential_name=OS_EXT_OCI
- here we demo using the
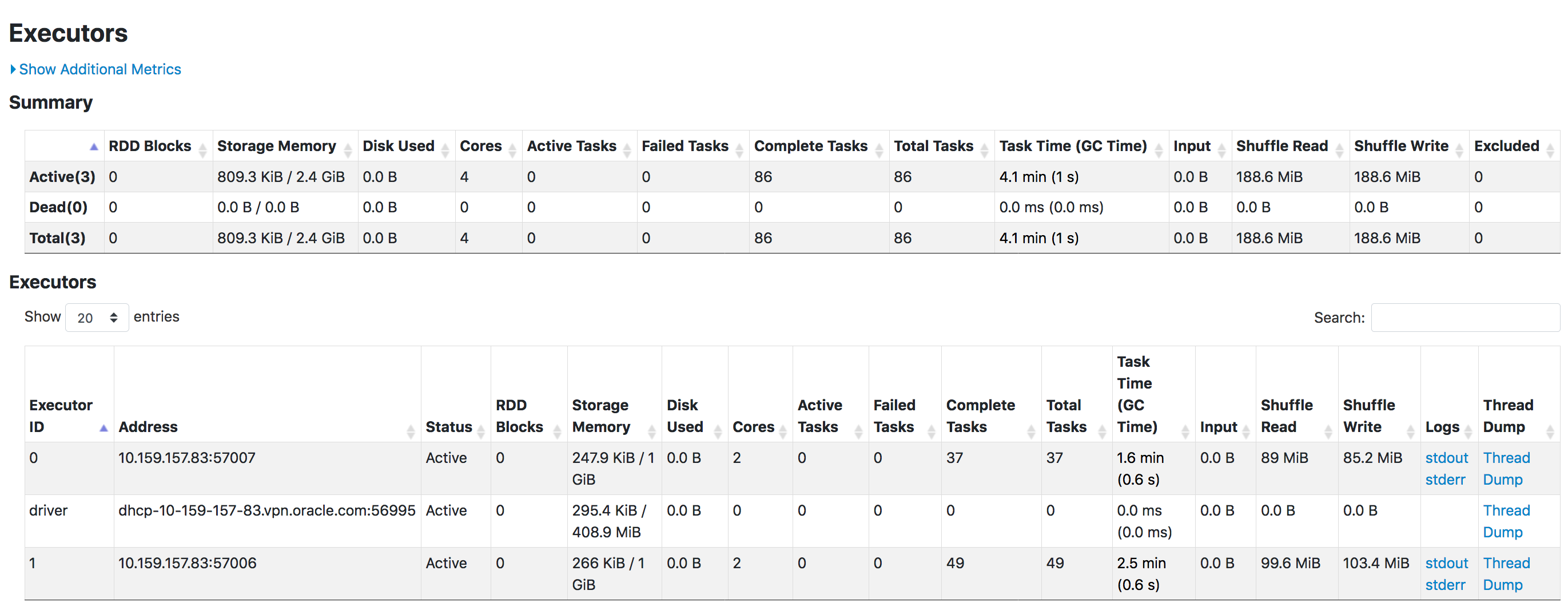
spark-shellon a 2 executor cluster. - Spark Oracle can be run on any type of cluster (embedded, spark-shell, thriftserver; standalone, yarn, kubernetes, mesos...)
bin/spark-shell --properties-file ~/hcluster/conf/spark.oracle.properties --master local-cluster[2,2,4096]
- Switch to the oracle catalog by issuing a
use oracle - You don't need this, you can qualify oracle tables by
oracleprefix.
(more detailed set of Catalog examples are here)
sql("use oracle").show()
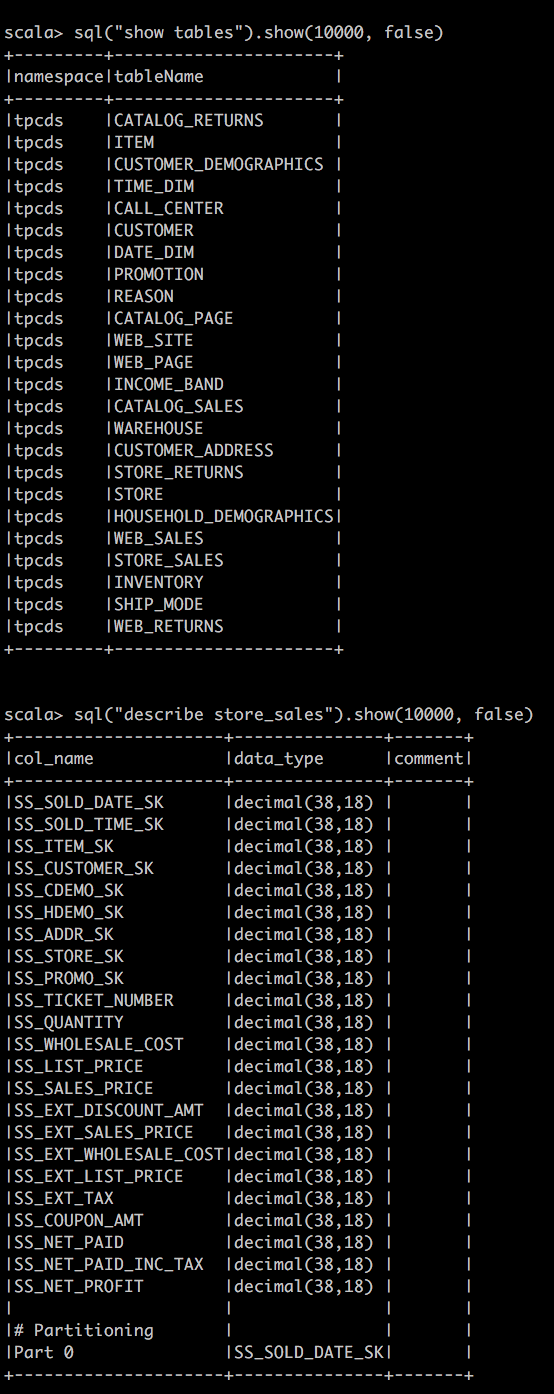
sql("show tables").show(10000, false)
sql("describe store_sales").show(10000, false)
// show partitions
sql("show partitions store_sales").show(1000, false)
// spark language extension to see oracle partitions properly
sql("show oracle partitions store_sales").show(1000, false)
- We have decent support of pushdown
- For TPCDS benchmark queries around 90 of 99 queries are completely pushed down.
- Here we demonstrate pushdown for a handful of representative queries
q1, q5, q69 and q89- queries are run on a tpcds scale 1 instance.
- Details on generated Oracle SQL can be found in Operator and Expression translation pages.
- Query is about identifying 'problem' customers.
- Query involves joins, aggregates, a CTE, a subquery expression, Order By
val q1 = s""" with customer_total_return as
(select sr_customer_sk as ctr_customer_sk
,sr_store_sk as ctr_store_sk
,sum(SR_RETURN_AMT) as ctr_total_return
from store_returns
,date_dim
where sr_returned_date_sk = d_date_sk
and d_year =2000
group by sr_customer_sk
,sr_store_sk)
select c_customer_id
from customer_total_return ctr1
,store
,customer
where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2
from customer_total_return ctr2
where ctr1.ctr_store_sk = ctr2.ctr_store_sk)
and s_store_sk = ctr1.ctr_store_sk
and s_state = 'TN'
and ctr1.ctr_customer_sk = c_customer_sk
order by c_customer_id
limit 100; """.stripMarginsql(q1).show(1000000, false)- runs in less than 1 second. Job has 1 task.
- The entire query is pushed to Oracle.
Query Plan:
sql(s"explain oracle pushdown $q1").show(1000, false)
|Project (1)
+- BatchScan (2)
(2) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "C_CUSTOMER_ID"
from ( select "C_CUSTOMER_ID"
from ( select "SR_CUSTOMER_SK" AS "ctr_customer_sk", "SR_STORE_SK" AS "ctr_store_sk", SUM("SR_RETURN_AMT") AS "ctr_total_return"
from TPCDS.STORE_RETURNS join TPCDS.DATE_DIM on ("SR_RETURNED_DATE_SK" = "D_DATE_SK")
where ((("SR_STORE_SK" IS NOT NULL AND "SR_CUSTOMER_SK" IS NOT NULL) AND "SR_RETURNED_DATE_SK" IS NOT NULL) AND ("D_YEAR" IS NOT NULL AND ("D_YEAR" = 2000.000000000000000000)))
group by "SR_CUSTOMER_SK", "SR_STORE_SK" ) join ( select "1_sparkora", "2_sparkora"
from ( select (AVG("ctr_total_return") * 1.2000000000000000000000) AS "1_sparkora", "ctr_store_sk" AS "2_sparkora"
from ( select "SR_STORE_SK" AS "ctr_store_sk", SUM("SR_RETURN_AMT") AS "ctr_total_return"
from TPCDS.STORE_RETURNS join TPCDS.DATE_DIM on ("SR_RETURNED_DATE_SK" = "D_DATE_SK")
where (("SR_STORE_SK" IS NOT NULL AND ("SR_RETURNED_DATE_SK" IS NOT NULL AND "SR_RETURNED_DATE_SK" IS NOT NULL)) AND ("D_YEAR" IS NOT NULL AND ("D_YEAR" = 2000.000000000000000000)))
group by "SR_CUSTOMER_SK", "SR_STORE_SK" )
group by "ctr_store_sk" )
where "1_sparkora" IS NOT NULL ) on (("ctr_store_sk" = "2_sparkora") AND (cast("ctr_total_return" as NUMBER(38, 20)) > "1_sparkora")) join TPCDS.STORE on ("ctr_store_sk" = "S_STORE_SK") join TPCDS.CUSTOMER on ("ctr_customer_sk" = "C_CUSTOMER_SK")
where ("ctr_total_return" IS NOT NULL AND ("S_STATE" IS NOT NULL AND ("S_STATE" = 'TN')))
order by "C_CUSTOMER_ID" ASC NULLS FIRST )
where rownum <= 100
Pushdown Oracle SQL, Query Splitting details:
Query is not split
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "false")
sql(q1).show(1000000, false)
- takes more than 20 secs. Each table is read into Spark.
- Only Scans pushed to Oracle.
sql(s"explain oracle pushdown $q1").show(1000, false)
|TakeOrderedAndProject (1)
+- Project (2)
+- SortMergeJoin Inner (3)
:- Project (4)
: +- SortMergeJoin Inner (5)
: :- Project (6)
: : +- SortMergeJoin Inner (7)
: : :- Filter (8)
: : : +- HashAggregate (9)
: : : +- HashAggregate (10)
: : : +- Project (11)
: : : +- SortMergeJoin Inner (12)
: : : :- Project (13)
: : : : +- Filter (14)
: : : : +- BatchScan (15)
: : : +- Project (16)
: : : +- Filter (17)
: : : +- BatchScan (18)
: : +- Filter (19)
: : +- HashAggregate (20)
: : +- HashAggregate (21)
: : +- HashAggregate (22)
: : +- HashAggregate (23)
: : +- Project (24)
: : +- SortMergeJoin Inner (25)
: : :- Project (26)
: : : +- Filter (27)
: : : +- BatchScan (28)
: : +- Project (29)
: : +- Filter (30)
: : +- BatchScan (31)
: +- Project (32)
: +- Filter (33)
: +- BatchScan (34)
+- Project (35)
+- BatchScan (36)
(15) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "SR_CUSTOMER_SK", "SR_STORE_SK", "SR_RETURN_AMT", "SR_RETURNED_DATE_SK"
from TPCDS.STORE_RETURNS
where ("SR_STORE_SK" IS NOT NULL AND "SR_CUSTOMER_SK" IS NOT NULL) and "SR_RETURNED_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(18) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_YEAR"
from TPCDS.DATE_DIM
where ("D_YEAR" IS NOT NULL AND ("D_YEAR" = 2000.000000000000000000))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(28) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "SR_CUSTOMER_SK", "SR_STORE_SK", "SR_RETURN_AMT", "SR_RETURNED_DATE_SK"
from TPCDS.STORE_RETURNS
where "SR_STORE_SK" IS NOT NULL and ("SR_RETURNED_DATE_SK" IS NOT NULL AND "SR_RETURNED_DATE_SK" IS NOT NULL)
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(31) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_YEAR"
from TPCDS.DATE_DIM
where ("D_YEAR" IS NOT NULL AND ("D_YEAR" = 2000.000000000000000000))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(34) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "S_STORE_SK", "S_STATE"
from TPCDS.STORE
where ("S_STATE" IS NOT NULL AND ("S_STATE" = 'TN'))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(36) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "C_CUSTOMER_SK", "C_CUSTOMER_ID"
from TPCDS.CUSTOMER
Pushdown Oracle SQL, Query Splitting details:
Query is not split
- A Report across Sales, Web and Catalog channels
- Query involves joins, aggregates, unions, CTEs, rollup
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "true")
val q5 = s"""
with ssr as
(select s_store_id,
sum(sales_price) as sales,
sum(profit) as profit,
sum(return_amt) as returns,
sum(net_loss) as profit_loss
from
( select ss_store_sk as store_sk,
ss_sold_date_sk as date_sk,
ss_ext_sales_price as sales_price,
ss_net_profit as profit,
cast(0 as decimal(7,2)) as return_amt,
cast(0 as decimal(7,2)) as net_loss
from store_sales
union all
select sr_store_sk as store_sk,
sr_returned_date_sk as date_sk,
cast(0 as decimal(7,2)) as sales_price,
cast(0 as decimal(7,2)) as profit,
sr_return_amt as return_amt,
sr_net_loss as net_loss
from store_returns
) salesreturns,
date_dim,
store
where date_sk = d_date_sk
and d_date between cast('2000-08-23' as date)
and date_add(cast('2000-08-23' as date), 14 )
and store_sk = s_store_sk
group by s_store_id)
,
csr as
(select cp_catalog_page_id,
sum(sales_price) as sales,
sum(profit) as profit,
sum(return_amt) as returns,
sum(net_loss) as profit_loss
from
( select cs_catalog_page_sk as page_sk,
cs_sold_date_sk as date_sk,
cs_ext_sales_price as sales_price,
cs_net_profit as profit,
cast(0 as decimal(7,2)) as return_amt,
cast(0 as decimal(7,2)) as net_loss
from catalog_sales
union all
select cr_catalog_page_sk as page_sk,
cr_returned_date_sk as date_sk,
cast(0 as decimal(7,2)) as sales_price,
cast(0 as decimal(7,2)) as profit,
cr_return_amount as return_amt,
cr_net_loss as net_loss
from catalog_returns
) salesreturns,
date_dim,
catalog_page
where date_sk = d_date_sk
and d_date between cast('2000-08-23' as date)
and date_add(cast('2000-08-23' as date), 14 )
and page_sk = cp_catalog_page_sk
group by cp_catalog_page_id)
,
wsr as
(select web_site_id,
sum(sales_price) as sales,
sum(profit) as profit,
sum(return_amt) as returns,
sum(net_loss) as profit_loss
from
( select ws_web_site_sk as wsr_web_site_sk,
ws_sold_date_sk as date_sk,
ws_ext_sales_price as sales_price,
ws_net_profit as profit,
cast(0 as decimal(7,2)) as return_amt,
cast(0 as decimal(7,2)) as net_loss
from web_sales
union all
select ws_web_site_sk as wsr_web_site_sk,
wr_returned_date_sk as date_sk,
cast(0 as decimal(7,2)) as sales_price,
cast(0 as decimal(7,2)) as profit,
wr_return_amt as return_amt,
wr_net_loss as net_loss
from web_returns left outer join web_sales on
( wr_item_sk = ws_item_sk
and wr_order_number = ws_order_number)
) salesreturns,
date_dim,
web_site
where date_sk = d_date_sk
and d_date between cast('2000-08-23' as date)
and date_add(cast('2000-08-23' as date), 14 )
and wsr_web_site_sk = web_site_sk
group by web_site_id)
select channel
, id
, sum(sales) as sales
, sum(returns) as returns
, sum(profit) as profit
from
(select 'store channel' as channel
, concat('store', s_store_id) as id
, sales
, returns
, (profit - profit_loss) as profit
from ssr
union all
select 'catalog channel' as channel
, concat('catalog_page', cp_catalog_page_id) as id
, sales
, returns
, (profit - profit_loss) as profit
from csr
union all
select 'web channel' as channel
, concat('web_site', web_site_id) as id
, sales
, returns
, (profit - profit_loss) as profit
from wsr
) x
group by rollup (channel, id)
order by channel
,id
limit 100
""".stripMarginsql(q5).show(1000000, false)- runs in less than 1 second. Job has 1 task.
-
The entire query is pushed to Oracle.
- rollup done as lateral inline join
Query Plan:
sql(s"explain oracle pushdown $q5").show(1000, false)
|Project (1)
+- BatchScan (2)
(2) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "channel_10_sparkora", "id_6_sparkora", "sales", "returns", "profit"
from ( select "channel_10_sparkora", "id_6_sparkora", SUM("sales") AS "sales", SUM("returns") AS "returns", SUM("profit") AS "profit"
from ( select SUM("sales_price") AS "sales", SUM("return_amt") AS "returns", (cast(SUM("profit") as NUMBER(38, 17)) - cast(SUM("net_loss") as NUMBER(38, 17))) AS "profit", 'store channel' AS "channel", CONCAT('store' , "S_STORE_ID") AS "id"
from ( select "SS_STORE_SK" AS "store_sk", "SS_SOLD_DATE_SK" AS "date_sk", "SS_EXT_SALES_PRICE" AS "sales_price", "SS_NET_PROFIT" AS "profit", 0E-18 AS "return_amt", 0E-18 AS "net_loss"
from TPCDS.STORE_SALES
where ("SS_STORE_SK" IS NOT NULL AND "SS_SOLD_DATE_SK" IS NOT NULL) UNION ALL select "SR_STORE_SK" AS "store_sk", "SR_RETURNED_DATE_SK" AS "date_sk", 0E-18 AS "sales_price", 0E-18 AS "profit", "SR_RETURN_AMT" AS "return_amt", "SR_NET_LOSS" AS "net_loss"
from TPCDS.STORE_RETURNS
where ("SR_STORE_SK" IS NOT NULL AND "SR_RETURNED_DATE_SK" IS NOT NULL) ) join TPCDS.DATE_DIM on ("date_sk" = "D_DATE_SK") join TPCDS.STORE on ("store_sk" = "S_STORE_SK")
where (("D_DATE" IS NOT NULL AND ("D_DATE" >= TRUNC(TIMESTAMP '2000-08-23 07:00:00.000000'))) AND ("D_DATE" <= TRUNC(TIMESTAMP '2000-09-06 07:00:00.000000')))
group by "S_STORE_ID" UNION ALL select SUM("sales_price") AS "sales", SUM("return_amt") AS "returns", (cast(SUM("profit") as NUMBER(38, 17)) - cast(SUM("net_loss") as NUMBER(38, 17))) AS "profit", 'catalog channel' AS "channel", CONCAT('catalog_page' , "CP_CATALOG_PAGE_ID") AS "id"
from ( select "CS_CATALOG_PAGE_SK" AS "page_sk", "CS_SOLD_DATE_SK" AS "date_sk", "CS_EXT_SALES_PRICE" AS "sales_price", "CS_NET_PROFIT" AS "profit", 0E-18 AS "return_amt", 0E-18 AS "net_loss"
from TPCDS.CATALOG_SALES
where ("CS_CATALOG_PAGE_SK" IS NOT NULL AND "CS_SOLD_DATE_SK" IS NOT NULL) UNION ALL select "CR_CATALOG_PAGE_SK" AS "page_sk", "CR_RETURNED_DATE_SK" AS "date_sk", 0E-18 AS "sales_price", 0E-18 AS "profit", "CR_RETURN_AMOUNT" AS "return_amt", "CR_NET_LOSS" AS "net_loss"
from TPCDS.CATALOG_RETURNS
where ("CR_CATALOG_PAGE_SK" IS NOT NULL AND "CR_RETURNED_DATE_SK" IS NOT NULL) ) join TPCDS.DATE_DIM on ("date_sk" = "D_DATE_SK") join TPCDS.CATALOG_PAGE on ("page_sk" = "CP_CATALOG_PAGE_SK")
where (("D_DATE" IS NOT NULL AND ("D_DATE" >= TRUNC(TIMESTAMP '2000-08-23 07:00:00.000000'))) AND ("D_DATE" <= TRUNC(TIMESTAMP '2000-09-06 07:00:00.000000')))
group by "CP_CATALOG_PAGE_ID" UNION ALL select SUM("sales_price") AS "sales", SUM("return_amt") AS "returns", (cast(SUM("profit") as NUMBER(38, 17)) - cast(SUM("net_loss") as NUMBER(38, 17))) AS "profit", 'web channel' AS "channel", CONCAT('web_site' , "WEB_SITE_ID") AS "id"
from ( select "WS_WEB_SITE_SK" AS "wsr_web_site_sk", "WS_SOLD_DATE_SK" AS "date_sk", "WS_EXT_SALES_PRICE" AS "sales_price", "WS_NET_PROFIT" AS "profit", 0E-18 AS "return_amt", 0E-18 AS "net_loss"
from TPCDS.WEB_SALES
where ("WS_WEB_SITE_SK" IS NOT NULL AND "WS_SOLD_DATE_SK" IS NOT NULL) UNION ALL select "WS_WEB_SITE_SK" AS "wsr_web_site_sk", "WR_RETURNED_DATE_SK" AS "date_sk", 0E-18 AS "sales_price", 0E-18 AS "profit", "WR_RETURN_AMT" AS "return_amt", "WR_NET_LOSS" AS "net_loss"
from TPCDS.WEB_RETURNS join TPCDS.WEB_SALES on (("WR_ITEM_SK" = "WS_ITEM_SK") AND ("WR_ORDER_NUMBER" = "WS_ORDER_NUMBER"))
where ("WR_RETURNED_DATE_SK" IS NOT NULL AND "WS_WEB_SITE_SK" IS NOT NULL) ) join TPCDS.DATE_DIM on ("date_sk" = "D_DATE_SK") join TPCDS.WEB_SITE on ("wsr_web_site_sk" = "WEB_SITE_SK")
where (("D_DATE" IS NOT NULL AND ("D_DATE" >= TRUNC(TIMESTAMP '2000-08-23 07:00:00.000000'))) AND ("D_DATE" <= TRUNC(TIMESTAMP '2000-09-06 07:00:00.000000')))
group by "WEB_SITE_ID" ) , lateral ( select "channel" "channel_10_sparkora", "id" "id_6_sparkora", 0 "spark_grouping_id_8_sparkora" from dual union all select "channel", null, 1 from dual union all select null, null, 3 from dual )
group by "channel_10_sparkora", "id_6_sparkora", "spark_grouping_id_8_sparkora"
order by "channel_10_sparkora" ASC NULLS FIRST, "id_6_sparkora" ASC NULLS FIRST )
where rownum <= 100
Pushdown Oracle SQL, Query Splitting details:
Query is not split
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "false")
sql(q5).show(1000000, false)
- takes couple of minutes to run. Each table is read into Spark.
- Only Scans pushed to Oracle.
sql(s"explain oracle pushdown $q5").show(1000, false)
|TakeOrderedAndProject (1)
+- HashAggregate (2)
+- HashAggregate (3)
+- Expand (4)
+- Union (5)
:- HashAggregate (6)
: +- HashAggregate (7)
: +- Project (8)
: +- SortMergeJoin Inner (9)
: :- Project (10)
: : +- SortMergeJoin Inner (11)
: : :- Union (12)
: : : :- Project (13)
: : : : +- Filter (14)
: : : : +- BatchScan (15)
: : : +- Project (16)
: : : +- Filter (17)
: : : +- BatchScan (18)
: : +- Project (19)
: : +- Filter (20)
: : +- BatchScan (21)
: +- Project (22)
: +- BatchScan (23)
:- HashAggregate (24)
: +- HashAggregate (25)
: +- Project (26)
: +- SortMergeJoin Inner (27)
: :- Project (28)
: : +- SortMergeJoin Inner (29)
: : :- Union (30)
: : : :- Project (31)
: : : : +- Filter (32)
: : : : +- BatchScan (33)
: : : +- Project (34)
: : : +- Filter (35)
: : : +- BatchScan (36)
: : +- Project (37)
: : +- Filter (38)
: : +- BatchScan (39)
: +- Project (40)
: +- BatchScan (41)
+- HashAggregate (42)
+- HashAggregate (43)
+- Project (44)
+- SortMergeJoin Inner (45)
:- Project (46)
: +- SortMergeJoin Inner (47)
: :- Union (48)
: : :- Project (49)
: : : +- Filter (50)
: : : +- BatchScan (51)
: : +- Project (52)
: : +- SortMergeJoin Inner (53)
: : :- Project (54)
: : : +- BatchScan (55)
: : +- Project (56)
: : +- Filter (57)
: : +- BatchScan (58)
: +- Project (59)
: +- Filter (60)
: +- BatchScan (61)
+- Project (62)
+- BatchScan (63)
(15) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "SS_STORE_SK", "SS_EXT_SALES_PRICE", "SS_NET_PROFIT", "SS_SOLD_DATE_SK"
from TPCDS.STORE_SALES
where "SS_STORE_SK" IS NOT NULL and "SS_SOLD_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(18) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "SR_STORE_SK", "SR_RETURN_AMT", "SR_NET_LOSS", "SR_RETURNED_DATE_SK"
from TPCDS.STORE_RETURNS
where "SR_STORE_SK" IS NOT NULL and "SR_RETURNED_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(21) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_DATE"
from TPCDS.DATE_DIM
where (("D_DATE" IS NOT NULL AND ("D_DATE" >= TRUNC(TIMESTAMP '2000-08-23 07:00:00.000000'))) AND ("D_DATE" <= TRUNC(TIMESTAMP '2000-09-06 07:00:00.000000')))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(23) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "S_STORE_SK", "S_STORE_ID"
from TPCDS.STORE
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(33) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "CS_CATALOG_PAGE_SK", "CS_EXT_SALES_PRICE", "CS_NET_PROFIT", "CS_SOLD_DATE_SK"
from TPCDS.CATALOG_SALES
where "CS_CATALOG_PAGE_SK" IS NOT NULL and "CS_SOLD_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(36) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "CR_CATALOG_PAGE_SK", "CR_RETURN_AMOUNT", "CR_NET_LOSS", "CR_RETURNED_DATE_SK"
from TPCDS.CATALOG_RETURNS
where "CR_CATALOG_PAGE_SK" IS NOT NULL and "CR_RETURNED_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(39) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_DATE"
from TPCDS.DATE_DIM
where (("D_DATE" IS NOT NULL AND ("D_DATE" >= TRUNC(TIMESTAMP '2000-08-23 07:00:00.000000'))) AND ("D_DATE" <= TRUNC(TIMESTAMP '2000-09-06 07:00:00.000000')))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(41) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "CP_CATALOG_PAGE_SK", "CP_CATALOG_PAGE_ID"
from TPCDS.CATALOG_PAGE
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(51) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "WS_WEB_SITE_SK", "WS_EXT_SALES_PRICE", "WS_NET_PROFIT", "WS_SOLD_DATE_SK"
from TPCDS.WEB_SALES
where "WS_WEB_SITE_SK" IS NOT NULL and "WS_SOLD_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(55) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "WR_ITEM_SK", "WR_ORDER_NUMBER", "WR_RETURN_AMT", "WR_NET_LOSS", "WR_RETURNED_DATE_SK"
from TPCDS.WEB_RETURNS
where "WR_RETURNED_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(58) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "WS_ITEM_SK", "WS_WEB_SITE_SK", "WS_ORDER_NUMBER"
from TPCDS.WEB_SALES
where "WS_WEB_SITE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(61) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_DATE"
from TPCDS.DATE_DIM
where (("D_DATE" IS NOT NULL AND ("D_DATE" >= TRUNC(TIMESTAMP '2000-08-23 07:00:00.000000'))) AND ("D_DATE" <= TRUNC(TIMESTAMP '2000-09-06 07:00:00.000000')))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(63) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "WEB_SITE_SK", "WEB_SITE_ID"
from TPCDS.WEB_SITE
Pushdown Oracle SQL, Query Splitting details:
Query is not split
- Identify customers with different buying behavior in 2 separate quarters
- Query involves joins, aggregates, subquery predicates
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "true")
val q69 = s"""
select
cd_gender,
cd_marital_status,
cd_education_status,
count(*) cnt1,
cd_purchase_estimate,
count(*) cnt2,
cd_credit_rating,
count(*) cnt3
from
customer c,customer_address ca,customer_demographics
where
c.c_current_addr_sk = ca.ca_address_sk and
ca_state in ('KY','GA','NM') and
cd_demo_sk = c.c_current_cdemo_sk and
exists (select *
from store_sales,date_dim
where c.c_customer_sk = ss_customer_sk and
ss_sold_date_sk = d_date_sk and
d_year = 2001 and
d_moy between 4 and 4+2) and
(not exists (select *
from web_sales,date_dim
where c.c_customer_sk = ws_bill_customer_sk and
ws_sold_date_sk = d_date_sk and
d_year = 2001 and
d_moy between 4 and 4+2) and
not exists (select *
from catalog_sales,date_dim
where c.c_customer_sk = cs_ship_customer_sk and
cs_sold_date_sk = d_date_sk and
d_year = 2001 and
d_moy between 4 and 4+2))
group by cd_gender,
cd_marital_status,
cd_education_status,
cd_purchase_estimate,
cd_credit_rating
order by cd_gender,
cd_marital_status,
cd_education_status,
cd_purchase_estimate,
cd_credit_rating
limit 100
""".stripMarginsql(q69).show(1000000, false)- runs in 2 seconds. Job has 1 task.
- The entire query is pushed to Oracle.
Query Plan:
sql(s"explain oracle pushdown $q69").show(1000, false)
|Project (1)
+- BatchScan (2)
(2) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "CD_GENDER", "CD_MARITAL_STATUS", "CD_EDUCATION_STATUS", "cnt1", "CD_PURCHASE_ESTIMATE", "cnt2", "CD_CREDIT_RATING", "cnt3"
from ( select "CD_GENDER", "CD_MARITAL_STATUS", "CD_EDUCATION_STATUS", COUNT(1) AS "cnt1", "CD_PURCHASE_ESTIMATE", COUNT(1) AS "cnt2", "CD_CREDIT_RATING", COUNT(1) AS "cnt3"
from TPCDS.CUSTOMER "sparkora_0" join TPCDS.CUSTOMER_ADDRESS on ("C_CURRENT_ADDR_SK" = "CA_ADDRESS_SK") join TPCDS.CUSTOMER_DEMOGRAPHICS on ("C_CURRENT_CDEMO_SK" = "CD_DEMO_SK")
where ((((("C_CURRENT_ADDR_SK" IS NOT NULL AND "C_CURRENT_CDEMO_SK" IS NOT NULL) AND "sparkora_0"."C_CUSTOMER_SK" IN ( select "SS_CUSTOMER_SK"
from TPCDS.STORE_SALES join TPCDS.DATE_DIM on ("SS_SOLD_DATE_SK" = "D_DATE_SK")
where ("SS_SOLD_DATE_SK" IS NOT NULL AND (((("D_YEAR" IS NOT NULL AND "D_MOY" IS NOT NULL) AND ("D_YEAR" = 2001.000000000000000000)) AND ("D_MOY" >= 4.000000000000000000)) AND ("D_MOY" <= 6.000000000000000000))) )) AND not exists ( select 1
from TPCDS.WEB_SALES join TPCDS.DATE_DIM on ("WS_SOLD_DATE_SK" = "D_DATE_SK")
where (("WS_SOLD_DATE_SK" IS NOT NULL AND (((("D_YEAR" IS NOT NULL AND "D_MOY" IS NOT NULL) AND ("D_YEAR" = 2001.000000000000000000)) AND ("D_MOY" >= 4.000000000000000000)) AND ("D_MOY" <= 6.000000000000000000))) AND ("sparkora_0"."C_CUSTOMER_SK" = "WS_BILL_CUSTOMER_SK")) )) AND not exists ( select 1
from TPCDS.CATALOG_SALES join TPCDS.DATE_DIM on ("CS_SOLD_DATE_SK" = "D_DATE_SK")
where (("CS_SOLD_DATE_SK" IS NOT NULL AND (((("D_YEAR" IS NOT NULL AND "D_MOY" IS NOT NULL) AND ("D_YEAR" = 2001.000000000000000000)) AND ("D_MOY" >= 4.000000000000000000)) AND ("D_MOY" <= 6.000000000000000000))) AND ("sparkora_0"."C_CUSTOMER_SK" = "CS_SHIP_CUSTOMER_SK")) )) AND "CA_STATE" IN ( 'KY', 'GA', 'NM' ))
group by "CD_GENDER", "CD_MARITAL_STATUS", "CD_EDUCATION_STATUS", "CD_PURCHASE_ESTIMATE", "CD_CREDIT_RATING"
order by "CD_GENDER" ASC NULLS FIRST, "CD_MARITAL_STATUS" ASC NULLS FIRST, "CD_EDUCATION_STATUS" ASC NULLS FIRST, "CD_PURCHASE_ESTIMATE" ASC NULLS FIRST, "CD_CREDIT_RATING" ASC NULLS FIRST )
where rownum <= 100
Pushdown Oracle SQL, Query Splitting details:
Query is not split
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "false")
sql(q69).show(1000000, false)
- takes more than 5 mins. Each table is read into Spark.
- Only Scans pushed to Oracle.
sql(s"explain oracle pushdown $q69").show(1000, false)
|TakeOrderedAndProject (1)
+- HashAggregate (2)
+- HashAggregate (3)
+- Project (4)
+- SortMergeJoin Inner (5)
:- Project (6)
: +- SortMergeJoin Inner (7)
: :- Project (8)
: : +- SortMergeJoin LeftAnti (9)
: : :- SortMergeJoin LeftAnti (10)
: : : :- SortMergeJoin LeftSemi (11)
: : : : :- Project (12)
: : : : : +- Filter (13)
: : : : : +- BatchScan (14)
: : : : +- Project (15)
: : : : +- SortMergeJoin Inner (16)
: : : : :- Project (17)
: : : : : +- BatchScan (18)
: : : : +- Project (19)
: : : : +- Filter (20)
: : : : +- BatchScan (21)
: : : +- Project (22)
: : : +- SortMergeJoin Inner (23)
: : : :- Project (24)
: : : : +- BatchScan (25)
: : : +- Project (26)
: : : +- Filter (27)
: : : +- BatchScan (28)
: : +- Project (29)
: : +- SortMergeJoin Inner (30)
: : :- Project (31)
: : : +- BatchScan (32)
: : +- Project (33)
: : +- Filter (34)
: : +- BatchScan (35)
: +- Project (36)
: +- Filter (37)
: +- BatchScan (38)
+- Project (39)
+- BatchScan (40)
(14) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "C_CUSTOMER_SK", "C_CURRENT_CDEMO_SK", "C_CURRENT_ADDR_SK"
from TPCDS.CUSTOMER
where ("C_CURRENT_ADDR_SK" IS NOT NULL AND "C_CURRENT_CDEMO_SK" IS NOT NULL)
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(18) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "SS_SOLD_TIME_SK", "SS_ITEM_SK", "SS_CUSTOMER_SK", "SS_CDEMO_SK", "SS_HDEMO_SK", "SS_ADDR_SK", "SS_STORE_SK", "SS_PROMO_SK", "SS_TICKET_NUMBER", "SS_QUANTITY", "SS_WHOLESALE_COST", "SS_LIST_PRICE", "SS_SALES_PRICE", "SS_EXT_DISCOUNT_AMT", "SS_EXT_SALES_PRICE", "SS_EXT_WHOLESALE_COST", "SS_EXT_LIST_PRICE", "SS_EXT_TAX", "SS_COUPON_AMT", "SS_NET_PAID", "SS_NET_PAID_INC_TAX", "SS_NET_PROFIT", "SS_SOLD_DATE_SK"
from TPCDS.STORE_SALES
where "SS_SOLD_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(21) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_DATE_ID", "D_DATE", "D_MONTH_SEQ", "D_WEEK_SEQ", "D_QUARTER_SEQ", "D_YEAR", "D_DOW", "D_MOY", "D_DOM", "D_QOY", "D_FY_YEAR", "D_FY_QUARTER_SEQ", "D_FY_WEEK_SEQ", "D_DAY_NAME", "D_QUARTER_NAME", "D_HOLIDAY", "D_WEEKEND", "D_FOLLOWING_HOLIDAY", "D_FIRST_DOM", "D_LAST_DOM", "D_SAME_DAY_LY", "D_SAME_DAY_LQ", "D_CURRENT_DAY", "D_CURRENT_WEEK", "D_CURRENT_MONTH", "D_CURRENT_QUARTER", "D_CURRENT_YEAR"
from TPCDS.DATE_DIM
where (((("D_YEAR" IS NOT NULL AND "D_MOY" IS NOT NULL) AND ("D_YEAR" = 2001.000000000000000000)) AND ("D_MOY" >= 4.000000000000000000)) AND ("D_MOY" <= 6.000000000000000000))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(25) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "WS_SOLD_TIME_SK", "WS_SHIP_DATE_SK", "WS_ITEM_SK", "WS_BILL_CUSTOMER_SK", "WS_BILL_CDEMO_SK", "WS_BILL_HDEMO_SK", "WS_BILL_ADDR_SK", "WS_SHIP_CUSTOMER_SK", "WS_SHIP_CDEMO_SK", "WS_SHIP_HDEMO_SK", "WS_SHIP_ADDR_SK", "WS_WEB_PAGE_SK", "WS_WEB_SITE_SK", "WS_SHIP_MODE_SK", "WS_WAREHOUSE_SK", "WS_PROMO_SK", "WS_ORDER_NUMBER", "WS_QUANTITY", "WS_WHOLESALE_COST", "WS_LIST_PRICE", "WS_SALES_PRICE", "WS_EXT_DISCOUNT_AMT", "WS_EXT_SALES_PRICE", "WS_EXT_WHOLESALE_COST", "WS_EXT_LIST_PRICE", "WS_EXT_TAX", "WS_COUPON_AMT", "WS_EXT_SHIP_COST", "WS_NET_PAID", "WS_NET_PAID_INC_TAX", "WS_NET_PAID_INC_SHIP", "WS_NET_PAID_INC_SHIP_TAX", "WS_NET_PROFIT", "WS_SOLD_DATE_SK"
from TPCDS.WEB_SALES
where "WS_SOLD_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(28) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_DATE_ID", "D_DATE", "D_MONTH_SEQ", "D_WEEK_SEQ", "D_QUARTER_SEQ", "D_YEAR", "D_DOW", "D_MOY", "D_DOM", "D_QOY", "D_FY_YEAR", "D_FY_QUARTER_SEQ", "D_FY_WEEK_SEQ", "D_DAY_NAME", "D_QUARTER_NAME", "D_HOLIDAY", "D_WEEKEND", "D_FOLLOWING_HOLIDAY", "D_FIRST_DOM", "D_LAST_DOM", "D_SAME_DAY_LY", "D_SAME_DAY_LQ", "D_CURRENT_DAY", "D_CURRENT_WEEK", "D_CURRENT_MONTH", "D_CURRENT_QUARTER", "D_CURRENT_YEAR"
from TPCDS.DATE_DIM
where (((("D_YEAR" IS NOT NULL AND "D_MOY" IS NOT NULL) AND ("D_YEAR" = 2001.000000000000000000)) AND ("D_MOY" >= 4.000000000000000000)) AND ("D_MOY" <= 6.000000000000000000))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(32) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "CS_SOLD_TIME_SK", "CS_SHIP_DATE_SK", "CS_BILL_CUSTOMER_SK", "CS_BILL_CDEMO_SK", "CS_BILL_HDEMO_SK", "CS_BILL_ADDR_SK", "CS_SHIP_CUSTOMER_SK", "CS_SHIP_CDEMO_SK", "CS_SHIP_HDEMO_SK", "CS_SHIP_ADDR_SK", "CS_CALL_CENTER_SK", "CS_CATALOG_PAGE_SK", "CS_SHIP_MODE_SK", "CS_WAREHOUSE_SK", "CS_ITEM_SK", "CS_PROMO_SK", "CS_ORDER_NUMBER", "CS_QUANTITY", "CS_WHOLESALE_COST", "CS_LIST_PRICE", "CS_SALES_PRICE", "CS_EXT_DISCOUNT_AMT", "CS_EXT_SALES_PRICE", "CS_EXT_WHOLESALE_COST", "CS_EXT_LIST_PRICE", "CS_EXT_TAX", "CS_COUPON_AMT", "CS_EXT_SHIP_COST", "CS_NET_PAID", "CS_NET_PAID_INC_TAX", "CS_NET_PAID_INC_SHIP", "CS_NET_PAID_INC_SHIP_TAX", "CS_NET_PROFIT", "CS_SOLD_DATE_SK"
from TPCDS.CATALOG_SALES
where "CS_SOLD_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(35) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_DATE_ID", "D_DATE", "D_MONTH_SEQ", "D_WEEK_SEQ", "D_QUARTER_SEQ", "D_YEAR", "D_DOW", "D_MOY", "D_DOM", "D_QOY", "D_FY_YEAR", "D_FY_QUARTER_SEQ", "D_FY_WEEK_SEQ", "D_DAY_NAME", "D_QUARTER_NAME", "D_HOLIDAY", "D_WEEKEND", "D_FOLLOWING_HOLIDAY", "D_FIRST_DOM", "D_LAST_DOM", "D_SAME_DAY_LY", "D_SAME_DAY_LQ", "D_CURRENT_DAY", "D_CURRENT_WEEK", "D_CURRENT_MONTH", "D_CURRENT_QUARTER", "D_CURRENT_YEAR"
from TPCDS.DATE_DIM
where (((("D_YEAR" IS NOT NULL AND "D_MOY" IS NOT NULL) AND ("D_YEAR" = 2001.000000000000000000)) AND ("D_MOY" >= 4.000000000000000000)) AND ("D_MOY" <= 6.000000000000000000))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(38) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "CA_ADDRESS_SK", "CA_STATE"
from TPCDS.CUSTOMER_ADDRESS
where "CA_STATE" IN ( 'KY', 'GA', 'NM' )
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(40) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "CD_DEMO_SK", "CD_GENDER", "CD_MARITAL_STATUS", "CD_EDUCATION_STATUS", "CD_PURCHASE_ESTIMATE", "CD_CREDIT_RATING"
from TPCDS.CUSTOMER_DEMOGRAPHICS
Pushdown Oracle SQL, Query Splitting details:
Query is not split
- Query is a report that has side-by-side comparison monthly sales and avg monthly sales
- Query involves join, aggregates, windowing
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "true")
val q89 = s"""
select *
from(
select i_category, i_class, i_brand,
s_store_name, s_company_name,
d_moy,
sum(ss_sales_price) sum_sales,
avg(sum(ss_sales_price)) over
(partition by i_category, i_brand, s_store_name, s_company_name)
avg_monthly_sales
from item, store_sales, date_dim, store
where ss_item_sk = i_item_sk and
ss_sold_date_sk = d_date_sk and
ss_store_sk = s_store_sk and
d_year in (1999) and
((trim(TRAILING from i_category) in ('Books','Electronics','Sports') and
trim(TRAILING from i_class) in ('computers','stereo','football')
)
or (trim(TRAILING from i_category) in ('Men','Jewelry','Women') and
trim(TRAILING from i_class) in ('shirts','birdal','dresses')
))
group by i_category, i_class, i_brand,
s_store_name, s_company_name, d_moy) tmp1
where case when (avg_monthly_sales <> 0) then (abs(sum_sales - avg_monthly_sales) / avg_monthly_sales) else null end > 0.1
order by sum_sales - avg_monthly_sales, s_store_name
limit 100""".stripMarginsql(q89).show(1000000, false)- runs in less than 1 second. Job has 1 task.
- The entire query is pushed to Oracle.
Query Plan:
sql(s"explain oracle pushdown $q89").show(1000, false)
|Project (1)
+- BatchScan (2)
(2) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "I_CATEGORY", "I_CLASS", "I_BRAND", "S_STORE_NAME", "S_COMPANY_NAME", "D_MOY", "sum_sales", "avg_monthly_sales"
from ( select "I_CATEGORY", "I_CLASS", "I_BRAND", "S_STORE_NAME", "S_COMPANY_NAME", "D_MOY", "sum_sales", "avg_monthly_sales"
from ( select "I_CATEGORY", "I_CLASS", "I_BRAND", "S_STORE_NAME", "S_COMPANY_NAME", "D_MOY", "sum_sales", "_w0", AVG("_w0") OVER ( PARTITION BY "I_CATEGORY", "I_BRAND", "S_STORE_NAME", "S_COMPANY_NAME" ) AS "avg_monthly_sales"
from ( select "I_CATEGORY", "I_CLASS", "I_BRAND", "S_STORE_NAME", "S_COMPANY_NAME", "D_MOY", SUM("SS_SALES_PRICE") AS "sum_sales", SUM("SS_SALES_PRICE") AS "_w0"
from TPCDS.ITEM join TPCDS.STORE_SALES on ("I_ITEM_SK" = "SS_ITEM_SK") join TPCDS.DATE_DIM on ("SS_SOLD_DATE_SK" = "D_DATE_SK") join TPCDS.STORE on ("SS_STORE_SK" = "S_STORE_SK")
where ((((TRIM(TRAILING FROM "I_CATEGORY") IN ( 'Books', 'Electronics', 'Sports' ) AND TRIM(TRAILING FROM "I_CLASS") IN ( 'computers', 'stereo', 'football' )) OR (TRIM(TRAILING FROM "I_CATEGORY") IN ( 'Men', 'Jewelry', 'Women' ) AND TRIM(TRAILING FROM "I_CLASS") IN ( 'shirts', 'birdal', 'dresses' ))) AND ("SS_STORE_SK" IS NOT NULL AND "SS_SOLD_DATE_SK" IS NOT NULL)) AND ("D_YEAR" IS NOT NULL AND ("D_YEAR" = 1999.000000000000000000)))
group by "I_CATEGORY", "I_CLASS", "I_BRAND", "S_STORE_NAME", "S_COMPANY_NAME", "D_MOY" ) )
where (CASE WHEN NOT("avg_monthly_sales" = 0E-22) THEN (cast(ABS((cast("sum_sales" as NUMBER(38, 17)) - cast("avg_monthly_sales" as NUMBER(38, 17)))) as NUMBER(38, 22)) / "avg_monthly_sales") ELSE null END > 0.100000)
order by (cast("sum_sales" as NUMBER(38, 17)) - cast("avg_monthly_sales" as NUMBER(38, 17))) ASC NULLS FIRST, "S_STORE_NAME" ASC NULLS FIRST )
where rownum <= 100
Pushdown Oracle SQL, Query Splitting details:
Query is not split
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "false")
sql(q89).show(1000000, false)
- takes more than 1 min. Each table is read into Spark.
- Only Scans pushed to Oracle.
sql(s"explain oracle pushdown $q89").show(1000, false)
|TakeOrderedAndProject (1)
+- Project (2)
+- Filter (3)
+- Window (4)
+- HashAggregate (5)
+- HashAggregate (6)
+- Project (7)
+- SortMergeJoin Inner (8)
:- Project (9)
: +- SortMergeJoin Inner (10)
: :- Project (11)
: : +- SortMergeJoin Inner (12)
: : :- Project (13)
: : : +- Filter (14)
: : : +- BatchScan (15)
: : +- Project (16)
: : +- Filter (17)
: : +- BatchScan (18)
: +- Project (19)
: +- Filter (20)
: +- BatchScan (21)
+- Project (22)
+- BatchScan (23)
(15) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "I_ITEM_SK", "I_BRAND", "I_CLASS", "I_CATEGORY"
from TPCDS.ITEM
where ((TRIM(TRAILING FROM "I_CATEGORY") IN ( 'Books', 'Electronics', 'Sports' ) AND TRIM(TRAILING FROM "I_CLASS") IN ( 'computers', 'stereo', 'football' )) OR (TRIM(TRAILING FROM "I_CATEGORY") IN ( 'Men', 'Jewelry', 'Women' ) AND TRIM(TRAILING FROM "I_CLASS") IN ( 'shirts', 'birdal', 'dresses' )))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(18) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "SS_ITEM_SK", "SS_STORE_SK", "SS_SALES_PRICE", "SS_SOLD_DATE_SK"
from TPCDS.STORE_SALES
where "SS_STORE_SK" IS NOT NULL and "SS_SOLD_DATE_SK" IS NOT NULL
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(21) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "D_DATE_SK", "D_YEAR", "D_MOY"
from TPCDS.DATE_DIM
where ("D_YEAR" IS NOT NULL AND ("D_YEAR" = 1999.000000000000000000))
Pushdown Oracle SQL, Query Splitting details:
Query is not split
(23) BatchScan
Oracle Instance:
DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
Pushdown Oracle SQL:
select "S_STORE_SK", "S_STORE_NAME", "S_COMPANY_NAME"
from TPCDS.STORE
Pushdown Oracle SQL, Query Splitting details:
Query is not split
When a pushdown query returns a lot of data, the single pipe between the Spark task and the database instance may become a bottleneck of query execution.
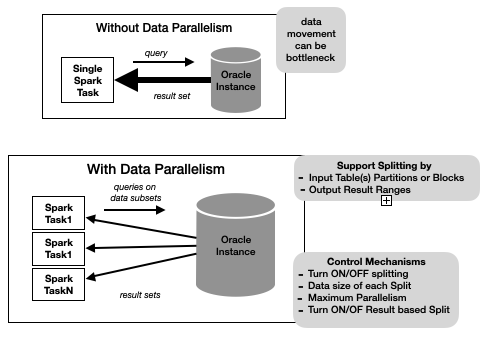
- Query Splitting attempts to split an oracle pushdown query into a set of queries such that the union-all of the results is the same as the original query result.
- The query can be split by Input Table(s) partitions or blocks or by the outputResult-Set row ranges.
- The work done to infer how a pushdown query is split is non-trivial and can incur a significant overhead. As shown in the diagram, we provide a set of knobs to control query splitting behavior.
- See Query Splitting guide for details.
To turn on query splitting set spark.sql.oracle.enable.querysplitting to true
On the TPCDS Queries(refer to tpcds query details page) Q16 is an example of partition splitting, Q35 is an example of block-based splitting and Q70 is an example of resultset based splitting.
- Scan partitioned table Store Sales
-
Notice
- with query splitting on, each task reads a bunch of partitions
- with splitting off, all data read in 1 task
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "true")
val store_sales_scan = """
select ss_item_sk, ss_ext_sales_price
from store_sales
where SS_SALES_PRICE > 50""".stripMargin
spark.sqlContext.setConf("spark.sql.oracle.enable.querysplitting", "true")
spark.sqlContext.setConf("spark.sql.oracle.querysplit.target", "1mb")
sql(s"explain oracle pushdown ${store_sales_scan}").show(10000, false)
sql(store_sales_scan).queryExecution.toRdd.map{iR => iR.numFields}.collect()
spark.sqlContext.setConf("spark.sql.oracle.enable.querysplitting", "false")
sql(s"explain oracle pushdown ${store_sales_scan}").show(10000, false)
sql(store_sales_scan).queryExecution.toRdd.map{iR => iR.numFields}.collect()- Scan non-partitioned table Customer
-
Notice
- with query splitting on, each task reads a rowId range
- with off, all data read in 1 task
-
spark.sql.oracle.querysplit.targetcan be used to control work per task.
val cd_scan = """
select CD_GENDER, CD_MARITAL_STATUS
from CUSTOMER_DEMOGRAPHICS
""".stripMargin
spark.sqlContext.setConf("spark.sql.oracle.enable.querysplitting", "true")
sql(s"explain oracle pushdown ${cd_scan}").show(10000, false)
sql(cd_scan).show(1000000, false)
spark.sqlContext.setConf("spark.sql.oracle.enable.querysplitting", "false")
sql(s"explain oracle pushdown ${cd_scan}").show(10000, false)
sql(cd_scan).show(1000000, false)Currently, we support Insert, Insert Overwrite and Delete on Oracle Tables. The operational are transactional, including when concurrent DML jobs are issued against an Oracle table. See DML Support page for details about the job and parameters to configure the job.
In the following we show:
- insert + delete into a non-partitioned table we introduce a shuffle in the source query to show write parallelism (the tasks run to quickly to demo recovery from task failure)
- Insert into a partitioned table
sql("""
create table if not exists spark_catalog.default.src_tab_for_writes(
C_CHAR_1 string ,
C_CHAR_5 string ,
C_VARCHAR2_10 string ,
C_VARCHAR2_40 string ,
C_NCHAR_1 string ,
C_NCHAR_5 string ,
C_NVARCHAR2_10 string ,
C_NVARCHAR2_40 string ,
C_BYTE tinyint ,
C_SHORT smallint ,
C_INT int ,
C_LONG bigint ,
C_NUMBER decimal(25,0),
C_DECIMAL_SCALE_5 decimal(25,5),
C_DECIMAL_SCALE_8 decimal(25,8),
C_DATE date ,
C_TIMESTAMP timestamp,
state string,
channel string
)
using parquet
OPTIONS (path "/Users/hbutani/newdb/spark-oracle/sql/src/test/resources/data/src_tab_for_writes")
""".stripMargin
).show(
sql("select count(*) from spark_catalog.default.src_tab_for_writes").show()
// parallelize write with lots of tasks
sql("set spark.sql.shuffle.partitions=29").show()
/* Example 1. INSERT NON-PARTITIONED TABLE */
sql("""
insert overwrite oracle.sparktest.unit_test_write
select distinct C_CHAR_1, C_CHAR_5, C_VARCHAR2_10, C_VARCHAR2_40, C_NCHAR_1, C_NCHAR_5,
C_NVARCHAR2_10, C_NVARCHAR2_40, C_BYTE, C_SHORT, C_INT, C_LONG, C_NUMBER,
C_DECIMAL_SCALE_5, C_DECIMAL_SCALE_8, C_DATE, C_TIMESTAMP
from spark_catalog.default.src_tab_for_writes
""").show()
sql("select count(*) from oracle.sparktest.unit_test_write").show()
/* Example 2. DELETE NON-PARTITIONED TABLE */
sql("delete from oracle.sparktest.unit_test_write where c_byte > 0").show()
sql("select count(*) from oracle.sparktest.unit_test_write").show()
/* Example 3. INSERT PARTITIONED TABLE */
sql("""insert overwrite oracle.sparktest.unit_test_write_partitioned partition(state = 'OR')
select c_varchar2_40, c_int, channel
from spark_catalog.default.src_tab_for_writes;
""").show()
sql("select state, count(*) from oracle.sparktest.unit_test_write_partitioned group by state").show()
sql("set spark.sql.shuffle.partitions=7").show()Consider the following data analysis task developed by someone who is more comfortable writing Spark code then SQL:
- define a 'problematic customers' dataset (variation of tpcds q1)
- define using Spark's DataFrame DSL
- build a feature Vector of each problem customer incident based on store characteristic
cust_ret_amt -> (tax_rate, num_emps, floor_space) - Run Regression to build prediction model based on these features.
- I am not an ML person; the example is probably nonsense, from a analysis perspective; it is only used to highlight pushdown to Oracle
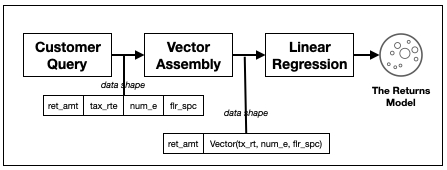
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "true")
spark.sqlContext.setConf("spark.sql.oracle.enable.querysplitting", "false")
sql("use oracle").show()
import spark.implicits._
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.ml.feature.LabeledPoint
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.LinearRegression
// STEP 1 : define a 'problematic customers' dataset
val store_rets = spark.table("store_returns")
val dates = spark.table("date_dim")
val customers = spark.table("customer")
val stores = spark.table("store")
val cust_store_rets = store_rets.
join(dates, $"sr_returned_date_sk" === $"d_date_sk").
where($"d_year" === 2000).
groupBy($"sr_customer_sk".as("ctr_customer_sk"), $"sr_store_sk".as("ctr_store_sk")).
agg(sum($"SR_RETURN_AMT").as("ctr_total_return"))
val avg_store_rets =
cust_store_rets.as("rets_2").
groupBy($"ctr_store_sk").
agg(avg("ctr_total_return").as("avg_store_returns"))
val prob_custs = cust_store_rets.as("rets_1").
join(customers, $"rets_1.ctr_customer_sk" === $"c_customer_sk").
join(stores, $"rets_1.ctr_store_sk" === $"s_store_sk").
join(avg_store_rets.as("rets_2"), $"rets_1.ctr_store_sk" === $"rets_2.ctr_store_sk").
where($"s_state" === "TN" and
$"rets_1.ctr_total_return" > ($"rets_2.avg_store_returns" * 1.2) and
$"s_tax_percentage".isNotNull and
$"s_number_employees".isNotNull and
$"s_floor_space".isNotNull).
select(($"ctr_total_return".cast(DoubleType)).as("ret_amt"),
$"s_tax_percentage".as("tax_rate"),
$"s_number_employees".as("num_emps"),
$"s_floor_space".as("floor_space")
)
// STEP 2: build a feature Vector
val assembler = new VectorAssembler().
setInputCols(Array("tax_rate", "num_emps", "floor_space")).
setOutputCol("features")
val cust_features = assembler.
transform(prob_custs).
map { r =>
LabeledPoint(r.getDouble(0), r.get(4).asInstanceOf[Vector])
}.toDF()
// STEP 3: Run Regression
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
val lrModel = lr.fit(cust_features)
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
val trainingSummary = lrModel.summary
println(s"numIterations: ${trainingSummary.totalIterations}")
println(s"objectiveHistory: [${trainingSummary.objectiveHistory.mkString(",")}]")
trainingSummary.residuals.show()
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}")
println(s"r2: ${trainingSummary.r2}")
The entire pipeline runs in couple of seconds Observe Pushdown even when Query defined using Spark code
println(cust_features.queryExecution.sparkPlan.treeString)
// as opposed to
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "false")
val cust_features = assembler.
transform(prob_custs).
map { r =>
LabeledPoint(r.getDouble(0), r.get(4).asInstanceOf[Vector])
}.toDF()
println(cust_features.queryExecution.sparkPlan.treeString)Whereas when spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "false")
model would involve reading the base tables into spark and doing the joins.
This takes considerably longer than with pushdown on.
These are capabilities that on the one hand extend Apache Spark SQL to utilize Oracle native functions and UDTs inside Spark SQL; and on the other hand translate code in Spark into code run in Oracle.
See Language Integration wiki page for details.
For example, we can register the STANDARD.SYS_CONTEXT oracle function to be used in
Spark SQL.
spark.sqlContext.setConf("spark.sql.oracle.enable.pushdown", "true")
import org.apache.spark.sql.oracle._
spark.registerOracleFunction(Some("STANDARD"), "SYS_CONTEXT")
sql("""
select oracle.sys_context('USERENV', 'CLIENT_PROGRAM_NAME') ora_client_pgm
from sparktest.unit_test
limit 1""".stripMargin
).show(10000, false)We can also register aggregation functions. For example:
spark.registerOracleFunction(None, "STRAGG")
sql(
"""
|select c_char_5, oracle.stragg(c_char_1)
|from sparktest.unit_test
|group by c_char_5""".stripMargin
).show(10000, false)Spark SQL Macros is a generic Spark capability developed by us. See more details about Spark SQL macros here
The basic idea behind Spark SQL macros is to convert the Scala code of a custom function into an equivalent Catalyst Expression. Using equivalent Catalyst expression in place of function invocations enable:
- better Plans
- more pushdown.
So consider a simple add 2 function. Registering and using it in vanilla
Spark leads to a Plan that cannot be pushed down:
spark.udf.register("intUDF", (i: Int) => {
val j = 2
i + j
})
spark.sql("""explain formatted
select intUDF(c_int)
from sparktest.unit_test
where intUDF(c_int) < 0
""".stripMargin
).show(10000, false)generates the following physical plan:
|== Physical Plan ==
Project (3)
+- * Filter (2)
+- BatchScan (1)
(1) BatchScan
Output [1]: [C_INT#2271]
OraPlan: 00 OraSingleQueryBlock [C_INT#2271], [oracolumnref(C_INT#2271)]
01 +- OraTableScan SPARKTEST.UNIT_TEST, [C_INT#2271]
ReadSchema: struct<C_INT:int>
dsKey: DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
oraPushdownSQL: select "C_INT"
from SPARKTEST.UNIT_TEST
(2) Filter [codegen id : 1]
Input [1]: [C_INT#2271]
Condition : (if (isnull(C_INT#2271)) null else intUDF(knownnotnull(C_INT#2271)) < 0)
(3) Project [codegen id : 1]
Output [1]: [if (isnull(C_INT#2271)) null else intUDF(knownnotnull(C_INT#2271)) AS intUDF(c_int)#2278]
Input [1]: [C_INT#2271]
- In the Plan both the Filter and Project operator have invocations of the UDF.
Whereas doing the same using our Macro mechanism, the entire query is pushed down: (notice the registration is almost identical to Spark's custom function registration.)
import org.apache.spark.sql.defineMacros._
spark.registerMacro("intUDM", spark.udm((i: Int) => {
val j = 2
i + j
}))
spark.sql("""explain formatted
select intUDM(c_int)
from sparktest.unit_test
where intUDM(c_int) < 0
""".stripMargin
).show(10000, false)generates the following physical plan:
|== Physical Plan ==
Project (2)
+- BatchScan (1)
(1) BatchScan
Output [1]: [(c_int + 2)#2316]
OraPlan: 00 OraSingleQueryBlock [(C_INT#2309 + 2) AS (c_int + 2)#2316], [oraalias((C_INT#2309 + 2) AS (c_int + 2)#2316)], orabinaryopexpression((((C_INT#2309 + 2) < 0) AND isnotnull(C_INT#2309)))
01 +- OraTableScan SPARKTEST.UNIT_TEST, [C_INT#2309]
ReadSchema: struct<(c_int + 2):int>
dsKey: DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
oraPushdownBindValues: 2, 0
oraPushdownSQL: select ("C_INT" + 2) AS "(c_int + 2)"
from SPARKTEST.UNIT_TEST
where ((("C_INT" + ?) < ?) AND "C_INT" IS NOT NULL)
(2) Project [codegen id : 1]
Output [1]: [(c_int + 2)#2316]
Input [1]: [(c_int + 2)#2316]- The predicate
intUDM(c_int) < 0becomes("C_INT" + ?) < ?(the literal in a predicate is converted to a bind value) - the projection
intUDM(c_int)becomes"C_INT" + 2. - since Macro calls are just plain old catalyst expressions, The Project and Filters are pushable to Oracle. So the entire query is collapsed into an Oracle Scan.
Consider tax and discount calculation defined as:
- no tax on groceries, alcohol is
10.5%, everything else is9.5% - on Sundays give a discount of
5%on alcohol.
import org.apache.spark.sql.defineMacros._
import org.apache.spark.sql.sqlmacros.DateTimeUtils._
import java.time.ZoneId
spark.registerMacro("taxAndDiscount", spark.udm({(prodCat : String, amt : Double) =>
val taxRate = prodCat match {
case "grocery" => 0.0
case "alcohol" => 10.5
case _ => 9.5
}
val currDate = currentDate(ZoneId.systemDefault())
val discount = if (getDayOfWeek(currDate) == 1 && prodCat == "alcohol") 0.05 else 0.0
amt * ( 1.0 - discount) * (1.0 + taxRate)
}))The Plan for the following query
spark.sql(
"""
|explain extended
|select i_item_id,
| taxAndDiscount(I_CATEGORY, I_CURRENT_PRICE) as taxAndDiscount
|from item""".stripMargin
).show(1000, false)
spark.sql(
"""
|explain formatted
|select i_item_id,
| taxAndDiscount(I_CATEGORY, I_CURRENT_PRICE) as taxAndDiscount
|from item""".stripMargin
).show(1000, false)is:
OUTPUT OF EXPLAIN EXTENDED:
|== Parsed Logical Plan ==
'Project ['i_item_id, 'taxAndDiscount('I_CATEGORY, 'I_CURRENT_PRICE) AS taxAndDiscount#1075]
+- 'UnresolvedRelation [item], [], false
== Analyzed Logical Plan ==
i_item_id: string, taxAndDiscount: double
Project [i_item_id#1082, ((cast(I_CURRENT_PRICE#1086 as double) * (1.0 - if (((dayofweek(current_date(Some(America/Los_Angeles))) = 1) AND (I_CATEGORY#1093 = alcohol))) 0.05 else 0.0)) * (1.0 + CASE WHEN (I_CATEGORY#1093 = grocery) THEN 0.0 WHEN (I_CATEGORY#1093 = alcohol) THEN 10.5 ELSE 9.5 END)) AS taxAndDiscount#1075]
+- SubqueryAlias oracle.tpcds.item
+- RelationV2[I_ITEM_SK#1081, I_ITEM_ID#1082, I_REC_START_DATE#1083, I_REC_END_DATE#1084, I_ITEM_DESC#1085, I_CURRENT_PRICE#1086, I_WHOLESALE_COST#1087, I_BRAND_ID#1088, I_BRAND#1089, I_CLASS_ID#1090, I_CLASS#1091, I_CATEGORY_ID#1092, I_CATEGORY#1093, I_MANUFACT_ID#1094, I_MANUFACT#1095, I_SIZE#1096, I_FORMULATION#1097, I_COLOR#1098, I_UNITS#1099, I_CONTAINER#1100, I_MANAGER_ID#1101, I_PRODUCT_NAME#1102] TPCDS.ITEM
== Optimized Logical Plan ==
RelationV2[I_ITEM_ID#1082, taxAndDiscount#1075] TPCDS.ITEM
== Physical Plan ==
*(1) Project [I_ITEM_ID#1082, taxAndDiscount#1075]
+- BatchScan[I_ITEM_ID#1082, taxAndDiscount#1075] class org.apache.spark.sql.connector.read.oracle.OraPushdownScan
|
OUTPUT OF EXPLAIN FORMATTED:
|== Physical Plan ==
* Project (2)
+- BatchScan (1)
(1) BatchScan
Output [2]: [I_ITEM_ID#1121, taxAndDiscount#1114]
OraPlan: 00 OraSingleQueryBlock [I_ITEM_ID#1121, ((cast(I_CURRENT_PRICE#1125 as double) * 1.0) * (1.0 + CASE WHEN (I_CATEGORY#1132 = grocery) THEN 0.0 WHEN (I_CATEGORY#1132 = alcohol) THEN 10.5 ELSE 9.5 END)) AS taxAndDiscount#1114], [oracolumnref(I_ITEM_ID#1121), oraalias(((cast(I_CURRENT_PRICE#1125 as double) * 1.0) * (1.0 + CASE WHEN (I_CATEGORY#1132 = grocery) THEN 0.0 WHEN (I_CATEGORY#1132 = alcohol) THEN 10.5 ELSE 9.5 END)) AS taxAndDiscount#1114)]
01 +- OraTableScan TPCDS.ITEM, [I_ITEM_ID#1121, I_CURRENT_PRICE#1125, I_CATEGORY#1132]
ReadSchema: struct<I_ITEM_ID:string,taxAndDiscount:double>
dsKey: DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
oraPushdownSQL: select "I_ITEM_ID", ((cast("I_CURRENT_PRICE" as NUMBER(30, 15)) * 1.0d) * (1.0d + CASE WHEN ("I_CATEGORY" = 'grocery') THEN 0.0d WHEN ("I_CATEGORY" = 'alcohol') THEN 10.5d ELSE 9.5d END)) AS "taxAndDiscount"
from TPCDS.ITEM
(2) Project [codegen id : 1]
Output [2]: [I_ITEM_ID#1121, taxAndDiscount#1114]
Input [2]: [I_ITEM_ID#1121, taxAndDiscount#1114]
The analyzed expression for thetaxDiscount calculation is:
(
(cast(I_CURRENT_PRICE#1086 as double) *
(1.0 - if (((dayofweek(current_date(Some(America/Los_Angeles))) = 1) AND (I_CATEGORY#1093 = alcohol))) 0.05 else 0.0)) *
(1.0 + CASE WHEN (I_CATEGORY#1093 = grocery) THEN 0.0 WHEN (I_CATEGORY#1093 = alcohol) THEN 10.5 ELSE 9.5 END)
) AS taxAndDiscount#1075In the generated Oracle, the discount calculation is replaced by 1.0 because the day this explain
was run was a Tuesday(constant folding of discount calc) = i_current_price * (1.0 - 0.0) * (1.0 + taxRate)
(
(cast("I_CURRENT_PRICE" as NUMBER(30, 15)) * 1.0d) *
(1.0d + CASE WHEN ("I_CATEGORY" = 'grocery') THEN 0.0d WHEN ("I_CATEGORY" = 'alcohol') THEN 10.5d ELSE 9.5d END)
) AS "taxAndDiscount"This expression is pushed to Oracle SQL.