Query Splitting
When a pushdown query returns a lot of data, the single pipe between the Spark task and the database instance may become a bottleneck of query execution.
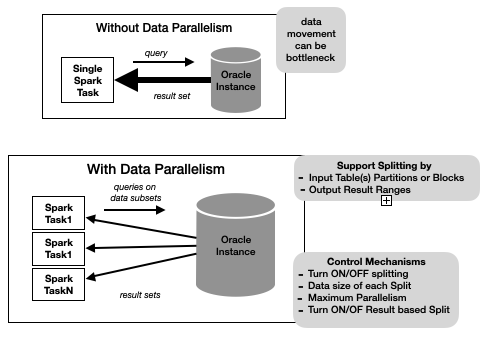
Query Splitting attempts to split an Oracle pushdown query into a set of queries such that the union-all of the results is the same as the original query result. The query can be split by input table(s) partitions or blocks or by the result-set row ranges. The work done to infer how a pushdown query is split is non-trivial and can incur a significant overhead. As shown in the diagram, we provide a set of knobs to control query splitting behavior.
Each split query is invoked in a separate partition of the OraScan.
Query splitting is triggered when Spark requests the OraScan instance for
planInputPartitions or outputPartitioning
The process of inferring Query splits runs an explain on
the pushdown query. For certain kinds of splitting it runs several other recursive calls against the Oracle instance.
This may incur an overhead of hundreds of mSecs ( For example, our testing on the TPCDS querySet indicates that complex pushdown queries evaluating explain take 1-3 seconds).
In low latency query response situations, this overhead maybe too high (higher than the time to execute the query).
So we provide a flag spark.sql.oracle.enable.pushdown, which controls if query splitting is attempted.
Set it to false if you don't want query splitting to be attempted. In this case pushdown queries will be run from 1 task in Spark. Typically low latency queries return small amounts of data, so setting up a single task is reasonable. In the future we may provide a mechanism for users to specify custom split strategy.
The setting spark.sql.oracle.querysplit.target controls the threshold query result set size (specify with byte units such as 1MB, 500kb,.. default unit is bytes.)
beyond which we attempt to split a pushdown query. The default value for this is 1MB.
But we temper the fetch parallelism by also allowing control of a max number of fetch tasks.
The setting spark.sql.oracle.querysplit.maxfetch.rounds indirectly controls the maximum
number of fetch tasks. The maximum fetch tasks = cluster_executor_cores * this_value.
So suppose spark.sql.oracle.querysplit.target=1MB; the query result size is 100MB, the
cluster_cores=8, and this_value is 1. That means even though according to the
querysplit.target setting we should have 100 tasks; we will be restricted to
8 tasks(= 8 * 1).
When splitting by OraResultSplit,
this is an important refrain for complex queries where the cost of running a query in each task must be balanced against the gain of concurrent fetching of the result set.
The maxfetch.rounds setting can be less then '1'; so setting to 0.5 in the scenario above will restrict the total fetch tasks to 4.
By allowing the restriction to take into account Spark cluster parallelism,
the admin can try to balance maximizing Spark cluster usage, minimizing result set fetch cost and minimizing query execution cost in Oracle.
The following provides details on [schemes for splitting](Splitting Schemes and Split Generation), [what schemes apply to different classes of Queries](Pushdown Query Split Analysis), [pushdown plan stats gathering](Pushdown Plan Analysis), and the [overall splitting process](Splitting Strategy).
The Query Split Analyzer
encapsulates logic for analyzing an OraPlan
and its associated LogicalPlan
and coming up with potential SplitCandidates:
which are OraJoinClauses
with associated OraTableScan or
straight-up OraTableScans on which OraPartitionSplit
or OraRowIdSplit could be
applied.
In general a 'non-trivial' pushdown query can only be split by OraResultSplit strategy since semantically the result of the pushdown query in Spark is the union-all of the output of the rdd partition of the bridge DataSourceV2ScanRelation.
But for certain query patterns we can split on a table involved in the query by OraPartitionSplit or OraRowIdSplit.
Here are a few examples (we anticipate this list will grow over time):
- A
select .. from tabRef where ...involving only one table can be split on that table. - A
select .. from tabRef1, tRef2,... where ...'''involving multiple tables inner joined''' can be split on any of the tables. But arbitrary choice of the split may lead to significant extra processing in the Oracle instance. A good choice is to choose the table that is significantly larger (say at least 10 times larger) than any of the other tables. This is an good indicator of a star-join, where we split on the 'fact' table. In case of ''outer joins'' the null-supplying side can be split. - Other split rules in the future could choose to split on the joining columns using
CREATE_CHUNKS_BY_NUMBER_COLfrom thedbms_parallel_executepackage. - An
Agg-Joinplan:select gBy_exprs, aggExprs from tabRef1, tRef2,... where ...where there exists groupExprs that refer to a column can be split on that column. For exampleselect cust_name, avg(sales) from sales join cust ... group by cust_namecan be split oncust_name. Furtherselect to_date(product_intro_date), cust_name, avg(sales) from sales join cust join product ...can also be split on cust_name. This split can cause a lot of extra work on the Oracle side. Since blocks contain arbitrary column values, each query split task could end up doing the same work as a single query.- Certain situations perform better:
- If the grouping column is also a partition column.
- If the column is a low cardinality column with an index.
- For star-joins if the grouping column is an alternate key(so it is functionally determined by the dimension key) then we can partition on the dimension key and drive the fact join via a join index.
So for example if
customer_nameis a unique identifier forcustomerwe can partition on customer_key ranges.
- Certain situations perform better:
Currently we only generate split candidates for single table queries or inner join queries.
The Query Split Analyzer doesn't decide on the actual split strategy to use.
It only identifies SplitCandidates.
(In the future we may extend this to be specific columns in a candidate table).
So for example for Join queries it only identifies that all joining tables are candidates. Picking a table for splitting is done by the Splitting Strategy.
Algorithm for Splitting a Pushdown Query.
Step 0:
- If
spark.sql.oracle.enable.pushdownis false return NoSplitStrategy
Step 1 : Analyze the OraPlan for splitting
- Run it through the Pushdown Query Split Analysis
- Obtain a SplitScope
Step 2: Get Pushdown Query Plan statistics
- Get overall query
rowCount, bytesand TableAccessOperations if there is scope for partition or row splitting.
Step 3: Decide on SplitStrategy
- If
planComplex && !resultSplitEnabled, then decide on NoSplitStrategy- A plan is complex if it has no candidate tables for splitting.
- Since OraResultSplit
may lead to much extra work on the Oracle instance, users can turn it off with the setting
spark.sql.oracle.allow.splitresultset.
- Otherwise try to identify a table to split based on SplitCandidates
- Choose the table with the largest amount of bytes read.
- Chosen table must have 10 times more bytes read than any other. TableAccessOperation
- Have the Split Generator generate splits based on query stats and optionally a target split table.
Given a query's output statistics (bytes, rowCount) and a potential targetTable, the Split Generator creates splits using the following rules and procedures:
degree_of_parallelism = outputBytes / bytesPerTask
numSplits = Math.min(
Math.ceil(degree_of_parallel).toInt,
Math.max(maxFetchTasks, 2)
)
rowsPerSplit = Math.ceil(rowCount / numSplits.toDouble).toInt- If
dop <= 1returns a split list of one containing the OraNoSplit split. - If there is no
target tablesplit by result_set into a list of OraResultSplit Each split containsrowsPerSplit. For example if the estimate10150rows and we estimate12splits then each split contains846rows (the last one has 2 less). If the statistic estimates are high, then some of the last splits may contain no rows. On the other, hand a low estimate may lead to the last split fetching a lot of data. - When there is a
target tableand the TableAccessDetails has a list of targeted partitions, we distribute the partitions intonumSplits. This assumes partitions are approximately the same size. Generate a list of OraPartitionSplit where each Split contains one or more partitions. - When there is a
target tableand there is no list of targeted partitions we split based onrowIdranges. We use the DBMS_PARALLEL_PACKAGE to compute row chunks. The user of the Catalog connection must haveCREATE JOB system privilege. The Splits are setup by invokingDBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWIDwithchunk_size = rowsPerSplit
Explain Plan Reader
invokes ORAMetadataSQLs queryPlan to get the Oracle plan in XML form.
It then extracts the overall plan statistics and when extractTabAccess = true extracts
''Table Access Operations'' and build TableAccessOperation structs.
The PlanInfo
is built and returned.