Write Path Flow
There are 2 write paths:
- Write from a Spark native plan to an OracleTable
- Write from a DataSourceV2ScanRelation of a OraScan
These will be Spark plans with the sink of the write being an OracleTable.
Spark optimizer will set up such a plan in all cases.
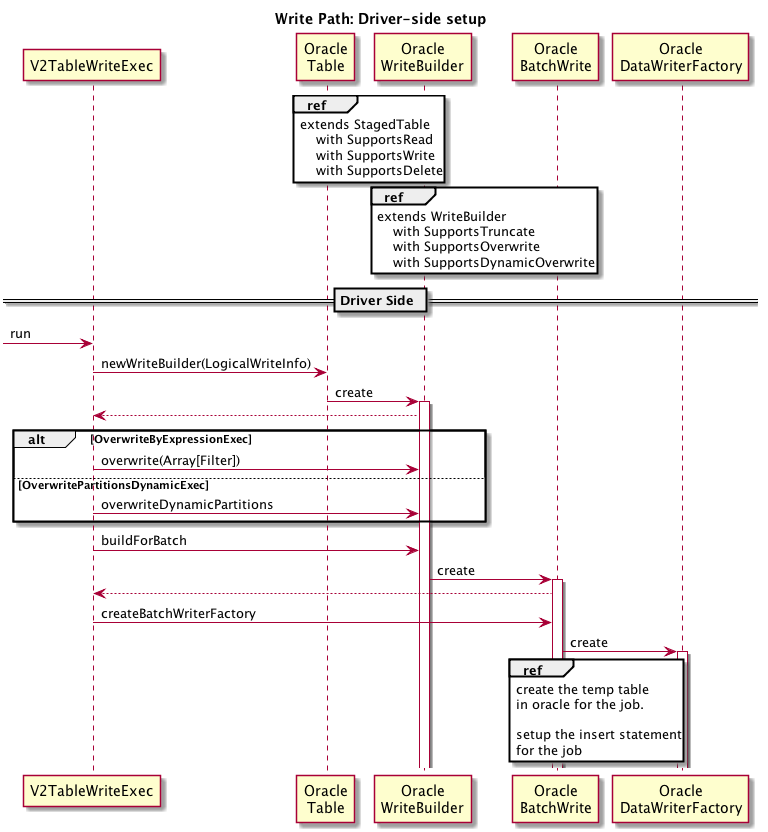
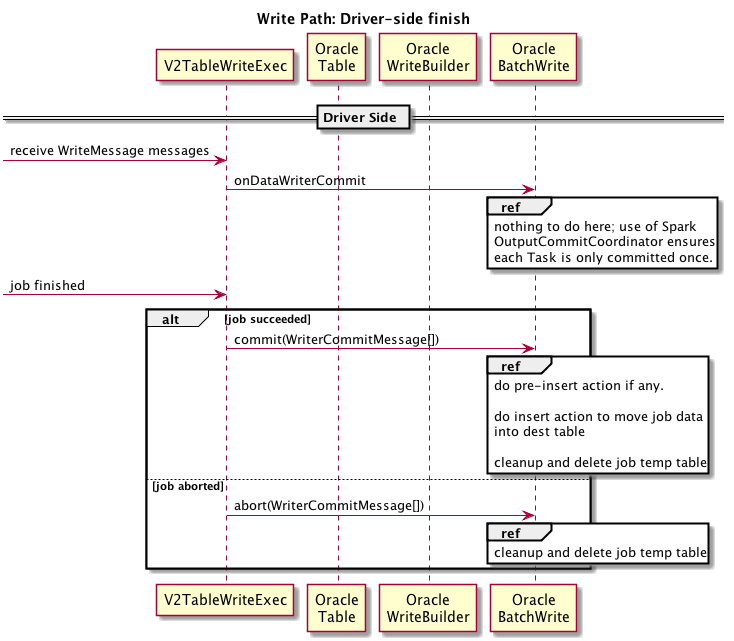
The execution of such a plan is divided into three stages: driver-side Init, executor-side task execution and driver-side job finishing. There are three kinds of writes done on the Oracle side to the destination table: APPEND rows, UPDATE rows (done as delete existing rows + insert new rows) and partition exchange. The assumption is that the oracle JDBC connection configured in Spark has the privilege to create tables.
Driver Side Setup flow:
Executor Side task execution:

Driver Side Finish flow:
-
The one logical optimization we may do in the future is to inject a shuffle when writing to a partitioned table. This will ensure each task writes to few oracle partitions.
-
A physical rewrite rule we plan to add is to check if the input plan of such plan is a DataSourceV2ScanExecBase on an
OraScanwe will rewrite this into the second case.