checklist for a blog post referencing an item from Digital Collections
- fetch origin from spec-lumber repository in GitHub Desktop
- create new markdown file in Visual Studio Code
- add frontmatter to post
- add digital objects to post
- preview your post
- push changes (this is a 3-step process)
- Open GitHub Desktop
- Set "Current Repository" to "spec-lumber"
- click "fetch origin"

- open GitHub Desktop and click "Open in Visual Studio Code." This will open the spec-lumber repository in Visual Studio Code
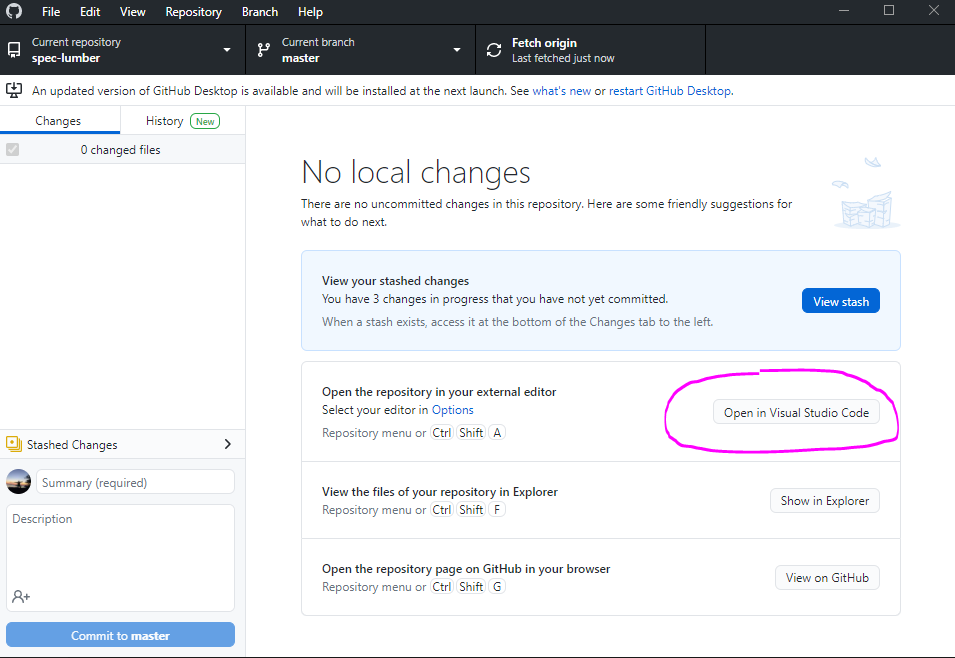
- in Visual Studio Code, click on "Terminal" and "New Terminal" in the top menu
- NOTE: make sure the terminal is set to "bash." The terminal should look similar to this:

If your terminal does NOT look like this, try the following:
- make sure you're viewing the "Terminal tab" (view tabs at top left of screenshot)
- make sure your terminal is using Bash. You can view different terminal types where it says "1: bash" in the screenshot and use the drop down menu to select the correct terminal.
- in Visual Studio Code, type
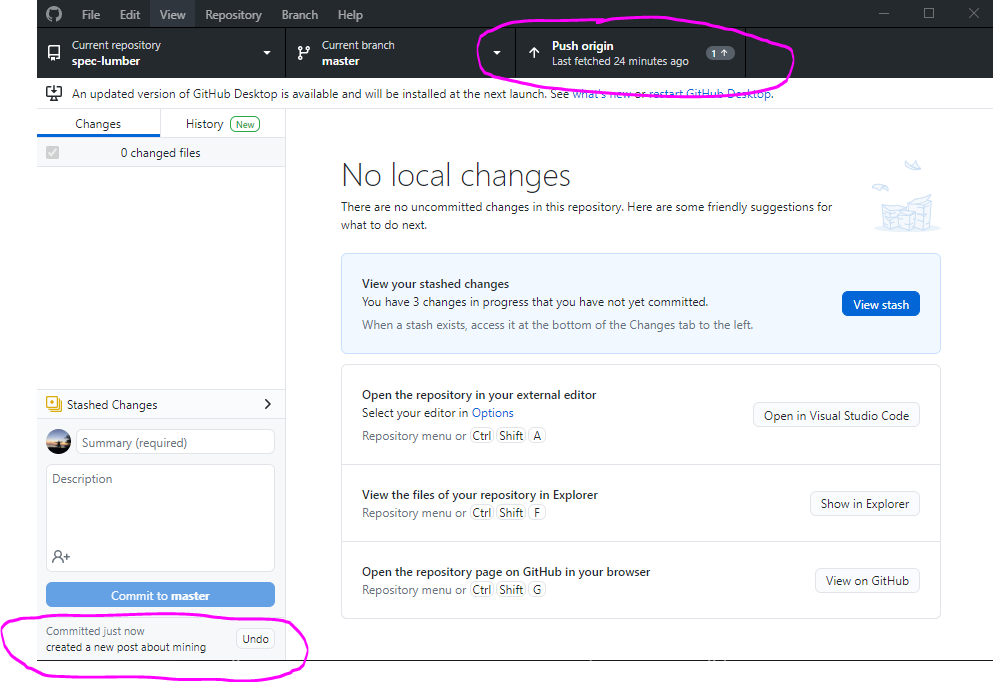
rake new_post title="title of post"into the terminal and hit the Enter key. A new post should be created in the_postsfolder (which you can find in the left-hand navigation menu in Visual Studio Code)- NOTE: the "date" field at the top of the blog post is what dictates when the post goes live on Harvester. The file name (left hand menu) includes the date, but has no effect on when the post goes live. BEST PRACTICE is to match these two dates to whenever you want the post to go live. To change the file name, right-click on the file name (left hand menu) and click "Rename."
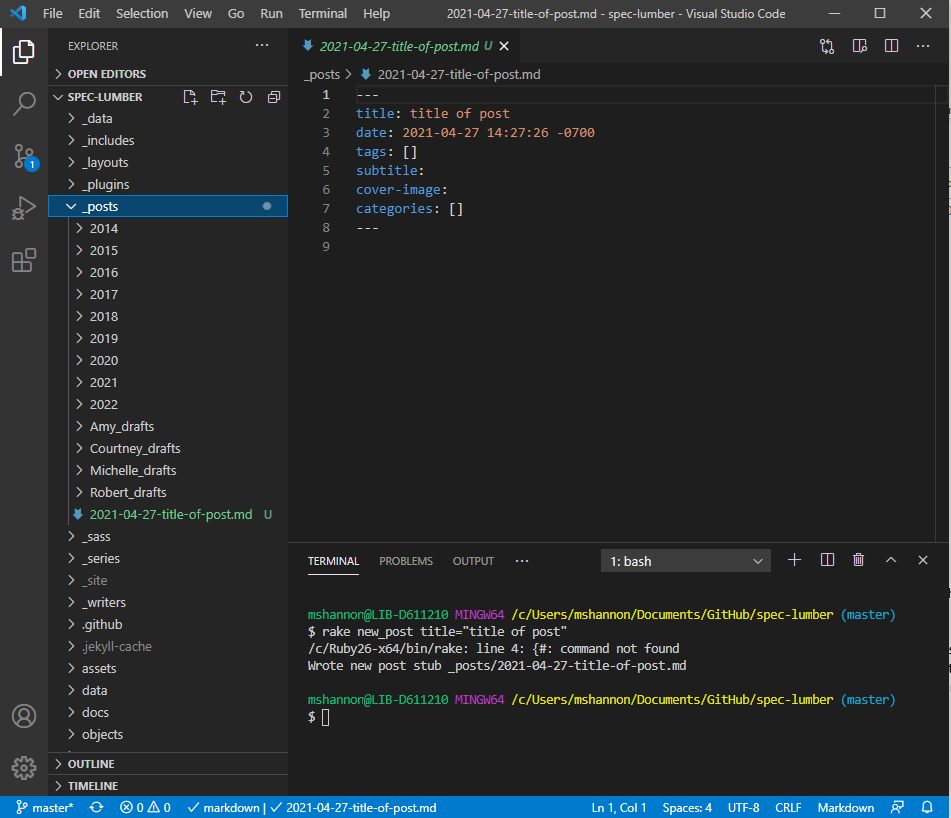
- in Visual Studio Code, open the new post you just created. Add the top fields as applicable.
- NOTE: referencing an existing digital collection for the
cover-imagemay require extra fields. See if your collection is in the Digital Collections and Paths For Harvester spreadsheet. Here are the options:-
cover-image-collection,cover-image -
cover-image-cdm-collection,cover-image-collection,cover-image -
cover-image: [insert link to object]If neither of the first two options work in the preview, this option will always work. Note that the link should be to the object, not the object page
-
- NOTE: check out Creating a Series and Adding a Post to a Series if your post is part of a series
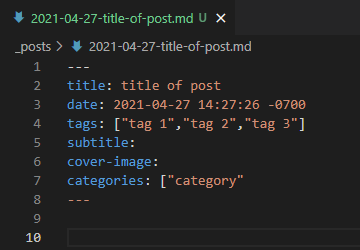
- NOTE: tags and categories must be formatted as follows, or it will break:
- NOTE: referencing an existing digital collection for the

- See if your collection is in the Digital Collections and Paths For Harvester spreadsheet
- there are three different types of includes for referencing an existing digital collection, depending on the factors listed in the spreadsheet above. Here are the three options:
{% include feature/digital-image.html collection="path" objectid=“objectid” %}{% include feature/digital-image.html cdm-collection="cdmid" collection="path" objectid="objectid" %}-
{% include feature/image.html objectid="link to object" link="link to page" caption="caption" %}If neither of the first two options work in the preview, this option is a fail-safe. This option will always work.
What's the reason behind these complicated include commands? Sometimes the url path for a CollectionBuilder collection is slightly different than its CONTENTdm collection url path. If that is the case, you'll need to add the cdm-collection variable. That's why it's important to check the Digital Collections and Paths For Harvester spreadsheet.
The `{% include feature/digital-image.html %} command is iterating over JSON files that can be found in the _data/digcoll/ folder. This data may not be totally current, or it may not be set up to serve your needs. It's possible the collection itself may need updating (check the branch and see when it was last updated, and if it needs to be updated, go ahead and merge the master and then let Olivia and Evan know).
It's also possible that the data included isn't up to date with the data from the collection. In this case, you'll need to download the json file for the collection from our data lake page, rename it with the url path of the collection, and update the repository.
This command is also based on collections that have items in CONTENTdm. If you're trying to include items from a standalone collection (like 1918flu), you'll need to treat the item like an external object.
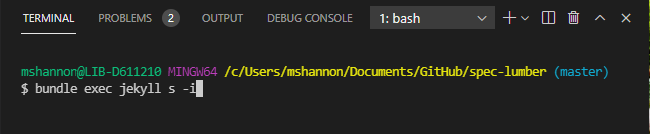
- when the content of your post has been written in Visual Studio Code, you can preview the post by typing
bundle exec jekyll s -iinto the terminal- NOTE: the date field at the top must be set for the present day or before. If the date is set for the future, you won't be able to view the post in the preview.
NOTE: if you receive a terminal error like this, it means there is an error in the code that is preventing it from fully parsing. The error will tell you which file, line, and column to look in, so you can narrow your search for the error. Here is the terminal error it will show you:

Here is the error (should be ["category"] with a closing bracket.
- Go to the Source Control view in Visual Studio Code
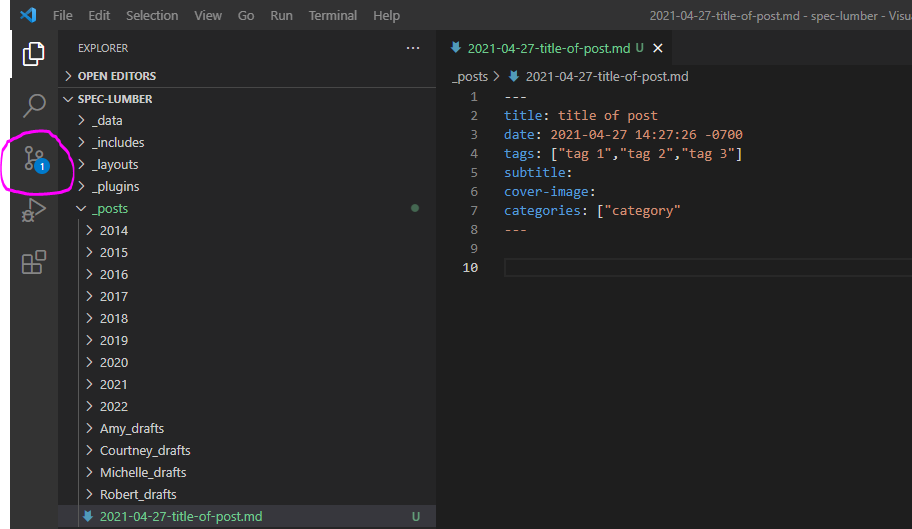
- click on the "+" (plus) symbol to stage your changes
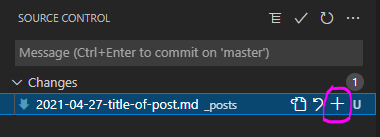
- once your changes are staged, add a descriptive message about what your changes are. Then click on the "checkmark" to commit your changes to your local GitHub repository on your local machine
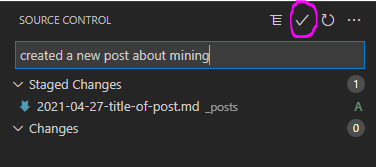
- open GitHub Desktop. You should see your descriptive message on the bottom left. If you've committed changes by accident, you can undo your commit here. If you want to push your commit, click on "Push Origin" at the top. This will push your commits to the cloud GitHub Repo, and will make your changes live on the Harvester website in approx. 5-10 minutes, or whenever the post is scheduled.
{kind=link}